================================================================================================================
Layer (type) Kernel Padding Stride Dilation Output Shape Param #
----------------------------------------------------------------------------------------------------------------
Conv2d-1 11 x 11 4 [-1, 96, 55, 55] 34,944
ReLU-2 [-1, 96, 55, 55] 0
MaxPool2d-3 3 2 [-1, 96, 27, 27] 0
Conv2d-4 5 x 5 2 [-1, 256, 27, 27] 614,656
ReLU-5 [-1, 256, 27, 27] 0
MaxPool2d-6 3 2 [-1, 256, 13, 13] 0
Conv2d-7 3 x 3 1 [-1, 384, 13, 13] 885,120
ReLU-8 [-1, 384, 13, 13] 0
Conv2d-9 3 x 3 1 [-1, 384, 13, 13] 1,327,488
ReLU-10 [-1, 384, 13, 13] 0
Conv2d-11 3 x 3 1 [-1, 256, 13, 13] 884,992
ReLU-12 [-1, 256, 13, 13] 0
MaxPool2d-13 3 2 [-1, 256, 6, 6] 0
Flatten-14 [-1, 9216] 0
Dropout-15 [-1, 9216] 0
Linear-16 [-1, 4096] 37,752,832
ReLU-17 [-1, 4096] 0
Dropout-18 [-1, 4096] 0
Linear-19 [-1, 4096] 16,781,312
ReLU-20 [-1, 4096] 0
Linear-21 [-1, 4] 16,388
================================================================================================================
Note: The `-1` in Output shape represents `batch_size`, which is flexible during program execution.
However, before you get started, we have several hints hopefully to make your life easier:
pip install matplotlib seaborn torch absl-py scikit-image tensorboard torchvision tqdm
python trainer.py --task_type=training --label_type=domain --learning_rate=0.001 --batch_size=128 --experiment_name=demo
class AlexNetLargeKernel
================================================================================================================
Layer (type) Kernel Padding Stride Dilation Output Shape Param #
----------------------------------------------------------------------------------------------------------------
Conv2d-1 21 x 21 1 8 [-1, 96, 27, 27] 127,104
ReLU-2 [-1, 96, 27, 27] 0
Conv2d-3 7 x 7 2 2 [-1, 256, 13, 13] 1,204,480
ReLU-4 [-1, 256, 13, 13] 0
Conv2d-5 3 x 3 1 [-1, 384, 13, 13] 885,120
ReLU-6 [-1, 384, 13, 13] 0
Conv2d-7 3 x 3 1 [-1, 384, 13, 13] 1,327,488
ReLU-8 [-1, 384, 13, 13] 0
Conv2d-9 3 x 3 2 [-1, 256, 6, 6] 884,992
ReLU-10 [-1, 256, 6, 6] 0
Flatten-11 [-1, 9216] 0
Dropout-12 [-1, 9216] 0
Linear-13 [-1, 4096] 37,752,832
ReLU-14 [-1, 4096] 0
Dropout-15 [-1, 4096] 0
Linear-16 [-1, 4096] 16,781,312
ReLU-17 [-1, 4096] 0
Linear-18 [-1, 4] 16,388
================================================================================================================
Please use the same optimal hyperparameter with Part I to train the new model, and report architecture and accuracy in your report.
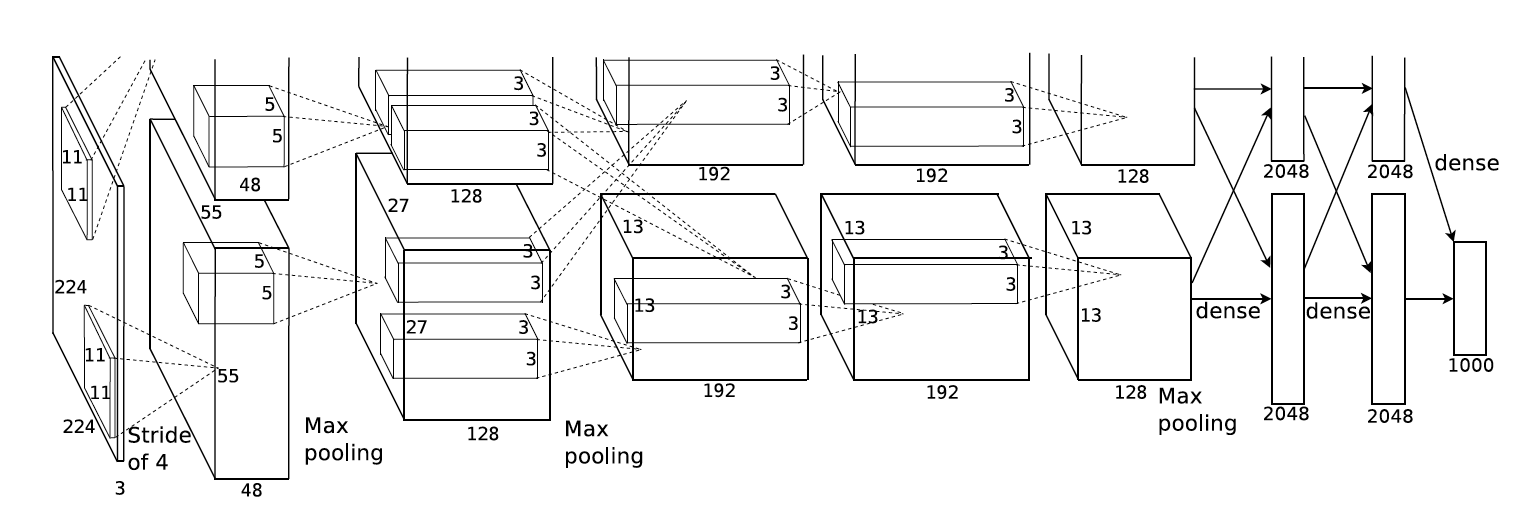
class AlexNetTiny
================================================================================================================
Layer (type) Kernel Padding Stride Dilation Output Shape Param #
----------------------------------------------------------------------------------------------------------------
Conv2d-1 11 x 11 4 [-1, 48, 55, 55] 17,472
ReLU-2 [-1, 48, 55, 55] 0
MaxPool2d-3 3 2 [-1, 48, 27, 27] 0
Conv2d-4 5 x 5 2 [-1, 128, 27, 27] 153,728
ReLU-5 [-1, 128, 27, 27] 0
MaxPool2d-6 3 2 [-1, 128, 13, 13] 0
Conv2d-7 3 x 3 1 [-1, 192, 13, 13] 221,376
ReLU-8 [-1, 192, 13, 13] 0
Conv2d-9 3 x 3 1 [-1, 192, 13, 13] 331,968
ReLU-10 [-1, 192, 13, 13] 0
Conv2d-11 3 x 3 1 [-1, 128, 13, 13] 221,312
ReLU-12 [-1, 128, 13, 13] 0
MaxPool2d-13 3 2 [-1, 128, 6, 6] 0
Flatten-14 [-1, 4608] 0
Dropout-15 [-1, 4608] 0
Linear-16 [-1, 2048] 9,439,232
ReLU-17 [-1, 2048] 0
Dropout-18 [-1, 2048] 0
Linear-19 [-1, 1024] 2,098,176
ReLU-20 [-1, 1024] 0
Linear-21 [-1, 4] 4,100
================================================================================================================
Please use the same optimal hyperparameter with Part I to train the new model, and report architecture and accuracy in your report.
class AlexNetAvgPooling
================================================================================================================
Layer (type) Kernel Padding Stride Dilation Output Shape Param #
----------------------------------------------------------------------------------------------------------------
Conv2d-1 11 x 11 4 [-1, 96, 55, 55] 34,944
ReLU-2 [-1, 96, 55, 55] 0
AvgPool2d-3 3 2 [-1, 96, 27, 27] 0
Conv2d-4 5 x 5 2 [-1, 256, 27, 27] 614,656
ReLU-5 [-1, 256, 27, 27] 0
AvgPool2d-6 3 2 [-1, 256, 13, 13] 0
Conv2d-7 3 x 3 1 [-1, 384, 13, 13] 885,120
ReLU-8 [-1, 384, 13, 13] 0
Conv2d-9 3 x 3 1 [-1, 384, 13, 13] 1,327,488
ReLU-10 [-1, 384, 13, 13] 0
Conv2d-11 3 x 3 1 [-1, 256, 13, 13] 884,992
ReLU-12 [-1, 256, 13, 13] 0
AvgPool2d-13 3 2 [-1, 256, 6, 6] 0
Flatten-14 [-1, 9216] 0
Dropout-15 [-1, 9216] 0
Linear-16 [-1, 4096] 37,752,832
ReLU-17 [-1, 4096] 0
Dropout-18 [-1, 4096] 0
Linear-19 [-1, 4096] 16,781,312
ReLU-20 [-1, 4096] 0
Linear-21 [-1, 4] 16,388
================================================================================================================
Please use the same optimal hyperparameter with Part I to train the new model, and report architecture and accuracy in your report.output = [input + 2 * padding - kernel - (kernel-1) * (dilation - 1)] / stride + 1Please copy your AlexNet to a new class named AlexNetDilation, and implement the model following the architectures given below.
class AlexNetDilation
================================================================================================================
Layer (type) Kernel Padding Stride Dilation Output Shape Param #
----------------------------------------------------------------------------------------------------------------
Conv2d-1 11 x 11 5 4 2 [-1, 96, 55, 55] 34,944
ReLU-2 [-1, 96, 55, 55] 0
MaxPool2d-3 3 2 [-1, 96, 27, 27] 0
Conv2d-4 5 x 5 4 2 [-1, 256, 27, 27] 614,656
ReLU-5 [-1, 256, 27, 27] 0
MaxPool2d-6 3 2 [-1, 256, 13, 13] 0
Conv2d-7 3 x 3 2 2 [-1, 384, 13, 13] 885,120
ReLU-8 [-1, 384, 13, 13] 0
Conv2d-9 3 x 3 2 2 [-1, 384, 13, 13] 1,327,488
ReLU-10 [-1, 384, 13, 13] 0
Conv2d-11 3 x 3 2 2 [-1, 256, 13, 13] 884,992
ReLU-12 [-1, 256, 13, 13] 0
MaxPool2d-13 3 2 [-1, 256, 6, 6] 0
Flatten-14 [-1, 9216] 0
Dropout-15 [-1, 9216] 0
Linear-16 [-1, 4096] 37,752,832
ReLU-17 [-1, 4096] 0
Dropout-18 [-1, 4096] 0
Linear-19 [-1, 4096] 16,781,312
ReLU-20 [-1, 4096] 0
Linear-21 [-1, 4] 16,388
================================================================================================================
Please use the same optimal hyperparameter with Part I to train the new model, and report architecture and accuracy in your report.