{kind=link}
{kind=link}
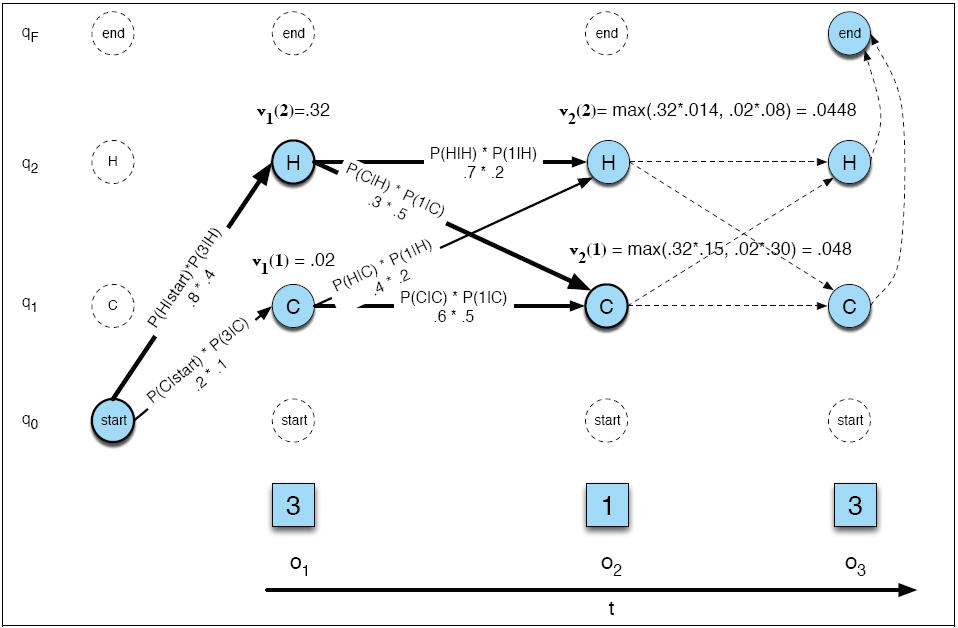
A partial Viterbi calculation is pictured here. This calculation takes us up through t=2 where v2(1) and v2(2) are computed. In the picture, the index 1 is used for the state labeled C and the index 2 is used for the state labeled H. Compute v3(1) and v3(2). You will need the transition and observation probabilities given here.
Think of this as filling in a table where the columns are moments in time and the rows are states in the HMM. Filling in the table with the numbers computed in the diagram above, and adding a column for time t = 0, and showing all the probability cells, it looks like this:
| end | 0 | 0 | 0 | |
|---|---|---|---|---|
| H | 0 | .32 | .0448 | |
| C | 0 | .02 | .048 | |
| start | 1.0 | 0 | 0 | |
| t = | 0 | 1 | 2 | 3 |
Each cell in the Viterbi table is filled with one of the Viterbi values computed in the diagram. Like the diagram, the table is complete through t=2. The values in the cells represent Viterbi probabilities. The Viterbi probability written as v2(2) represents the probability of the highest probability path that ends at state 2 at time 2.
Implement a non-probabilistic CKY parser.
The sample grammar file cfg.txt (click here to download) provided is exactly the same as the non-probabilistic
grammar in Figure 13.1 from the textbook . Your program should read in any grammar file in this .txt format, as we will test it with other grammars besides this one.
Also you can assume that letter casing is not problem. So you can lowercase everything or lowercase the first word of the sentence and accept the grammar as is.
The grammar provided has rules such as VP -> Verb NP PP,
which has more than two non-terminals on the right hand side. However,
the CKY algorithm can only handle grammars in a binarized format such
as CNF. Therefore, your program will need to binarize the grammar before CKY decoding
can be executed. You can't do this manually due to the blind testing of your program.
You should use the CNF conversion introduced in class.
Note that when using the binarized grammar, the parse tree generated by CKY will not be in its most natural form (because intermediate non-terminal symbols introduced by the binarization process may be present in the tree). Such parses are not considered as the final result. You should "debinarize" (the reverse of binarization) the tree to convert it back to its most natural form (no non-terminal that is not in the original grammar is permitted in the final output).
Example
Suppose that in your binarization process, the grammar rule VP -> Verb NP PP is broken into
VP -> Verb @VP.Verb @VP.Verb -> NP PP.
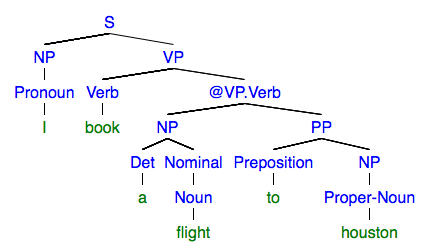
Using this grammar, your CKY produces the following parse tree for some sentence.
This tree is not in its most natural form because it contains the nonterminal symbol, @VP.Verb, which is not in the original grammar.
You need to post-process this tree to convert it to the following tree

Directly showing the tree containing non-terminals that are not in the original grammar as the answer without debinarization will result in point deduction!
The pattern to follow is the first element of a list is a parent node, and the rest of the elements in the list are children of that parent node. If a child has children of their own, then place in a list representing that sub-tree using the same format.[S [NP [Pronoun I]] [VP [Verb book] [NP [Det a] [Nominal [Noun flight]]] [PP [Preposition to] [NP [Proper-Noun houston]]]]](Copy and paste this string into mshang.ca/syntree to visualize it. You will find this tool very useful throughout this homework. )
⚠️ Warning
Failing to conform to the the input/output requirement will result in a 5-point deduction.
Your script (for Python users) or executable jar (for Java users) must take two parameters:
If you use Python, your code will be tested as:
python cky.py cfg.txt "A test sentence ."If you use Java, your code will be tested as:
java -cp yourname.jar cs1671.hw2.CKY cfg.txt "A test sentence ."The output should be printed to the standard output stream. Print the following information
Take a look at this probabilistic grammar taken from Figure 14.1 of the textbook. Notice that we have productions rules such as VP -> Verb NP PP,
which has more than two non-terminals on the right hand side.
1.00 S -> NP VP
1.00 PP -> P NP
0.70 VP -> V NP
0.30 VP -> VP PP
1.00 P -> with
1.00 V -> saw
0.40 NP -> NP PP
0.10 NP -> scientists
0.18 NP -> chins
0.04 NP -> saw
0.18 NP -> moons
0.10 NP -> telescopes
Submit a zip file containing the following pieces:
A writeup for the HMM portion(2.1) of the homework.
A writeup for the Probabilistic Parsing portion(2.3) of the homework.
And the CKY portion described below
For Python users, include:
cky.py.readme.txt which includes:
For Java users, include:
yourname-cky.zip archive which includes the Java source.yourname-cky.jar which is compiled from your source code. The jar should have a main class named cs1671.hw2.CKY.readme.txt which includes: