CS 2770: Homework 3
Due: 4/9/2019, 11:59pm
The main goal of this assignment is to make you familiar with the state of art object detection
methods. In this assignment, you will work on two datasets to explore the effective factors
in the performance of the object detection. You will be using Faster RCNN network pretrained on COCO dataset.
Since the datasets in this homework are different from the COCO, you need to further train the model
to fine tune it on our datasets.
One of the datasets contains 5 categories of objects and the other one is a dataset of pedestrian. In this assignment, you will separately train networks
for each of these datasets, compare their performance, and finally discuss the
possible reasons for the differences in performance. Considering the training time, this homework will take around 14 hours to complete.
The homework description has 5 parts. In part I, we have prepared the steps that
you need to follow to install required packages and download the datasets. In part II,
we have prepared an explanation for the object detection metric that you need to use in
your homework. In part III, you can find the list of packages that you need to
import in your code plus the way that you can create the dataloader for each dataset.
In part IV, you can find the steps that you need to follow to train and evaluate
your model. Finally in part V, we have prepared a complete explanation for the experiments
that you need to do for this assignment.
Training the CNN in this assignment may take
a long time, and several of you will be using the limited computing resources at the same time, so be sure to start this assignment early.
Part I: Installing Required Packages and Downloading Data
Installation:
- In this homework, you need to install new packages and libraries in an addition to the ones that you used in homework 2.
To install the required packages, we have prepared a script. After login to clusters first
you need to download the script with following command:
wget http://people.cs.pitt.edu/~nhonarvar/TA_Spring_2020/PyTorch_Installation_hw3.sh
- Then you need to run the script by the following command (Note: you just need to run this script once):
source PyTorch_Installation_hw3.sh
- After the successful execution of script, you need to run following command to exit the created virtual environment
at this point:
deactivate
Use PyTorch:
All of the steps to use PyTorch in this homework are the same as homework 2 except the name of virtual environment.
- In this step you need to transfer from login node to one of the GPUs node. On GPU cluster,
there exist four GPU partitions: gtx1080, titanx, k40, and titan (Note: you can find complete
explanation about all these partitions in this link).
One way to use these GPU partitions is to run an interactive job on clusters.
Here is an example of a command to submit a request to get access to one GPU of
titanx partition for 2 hours:
crc-interactive.py -g --time=2 -n 1 -c 1 -p titanx -u 1
After sending the request, you may or may not get access to any GPU because all of the GPUs of
partition might be in use. In the case that you are not able to get access to titanx partion, you can switch to other paritions
(gtx1080, k40, and titan) just by replacing the titanx with name of other partitions in command line. (Note: You need to wait
for 10-20 seconds to see whether you can get access to the requested GPU).
- Now (and any time in future that you want to use PyTorch) you must enter the virtual environment which has been created during the installation
by following two commands:
module load python/3.7.0 venv/wrap
workon pytorch_hw3
- At this point, you can run your python code by the following command:
python hw3.py
Download the Data and Required Packages:
- For this homework, we have prepared two datasets that you need to download in cluster and unzip as follows:
wget http://people.cs.pitt.edu/~nhonarvar/TA_Spring_2020/PASCAL.zip
unzip PASCAL.zip
wget http://people.cs.pitt.edu/~nhonarvar/TA_Spring_2020/PennFudanPed_hw3.zip
unzip PennFudanPed_hw3.zip
At this point you have a directory with name of PASCAL and a directory with name of PennFudanPed_hw3 which contain test, train and validation sets.
For PASCAL dataset, inside each of the train, test, and val directories, there exist three directories: 1) Images, 2) BBox and 3) Labels.
The images folder contains the images from PASCAL VOC dataset, the BBox folder contains the ground truth bounding boxes of objects in every image and the Labels contains
the object category for bounding boxes in every image. For PennFudanPed_hw3 dataset, there exist two directories: 1) Images and 2) Masks. The Images
folder contains images from Penn-Fudan dataset and Masks folder contains the segmentation mask of objects in every image.
- In this homework, you also need to put 6 python files in the same directoy that you are runing your code.
You can download the zip file which includes all of these python files with the following command:
wget http://people.cs.pitt.edu/~nhonarvar/TA_Spring_2020/Requied_Files.zip
unzip Requied_Files.zip
After unzipping the zip file, you need to copy all python files to the directory that you are running your code.
Part II: Object Detection Metric:
-
In homework 2 which was a classification task, we simply used accuracy as a metric to choose
the best model weight in training process. Computing the performance of object detection
is more complicated compared to object detection. The output of object detection are bounding
boxes and to compute the performance we use mAP (mean Average Precision). The definition of mAP is as follows:
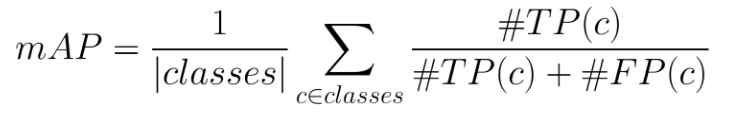 where
where
- True Positive - TP(c): a predicted bounding box (pred_bb) was made for class c, there is a ground truth bounding box (gt_bb) of class c, and IoU(pred_bb, gt_bb) >= threshold.
- False Positive - FP(c): a pred_bb was made for class c, and there is no gt_bb of class c. Or there is a gt_bb of class c, but IoU(pred_bb, gt_bb) < threshold.
For a given class c, to compute the Intersection over Union metric (IoU) (see image below) between any individual predicted bounding box and the ground truth bounding boxes, take the best overlap (i.e. the highest overlap between the predicted and any ground truth box) as your final score for that predicted bounding box. If there is no ground truth bounding box, but you predict a positive window, your score for that box is 0.

Part III: Import Required Libraries and Modules and Data Preparation
- In the first step in your homework, you need to import required modules and libraries:
import torch
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from pascal_dataset import PASCALDataset
import utils
from coco_utils import get_coco_api_from_dataset
from coco_eval import CocoEvaluator
import copy
import torch.optim as optim
from torch.optim import lr_scheduler
from PennFudanDataset import PennFudanDataset
- To represent our datasets, we have prepared the PASCALDataset class in pascal_dataset.py and PennFudanDataset class in PennFudanDataset.py. You can find
all the details of the way the images and annotations are converted to tensors in pascal_dataset.py and PennFudanDataset.py files.
You can use the PASCALDataset class and PennFudanDataset class in your code as follows:
dataset = PASCALDataset('path_to_data')
dataset = PennFudanDataset('path_to_data')
Note: The path to data is the path to train, test, or val sets NOT the directory
which includes the whole dataset. As the result, you need to create a separate dataset
for each of train, test and validation sets.
- In the next step, we need to create the data loader for the dataset. Here is an example
of the code to prepare the dataloader:
data_loader = torch.utils.data.DataLoader(dataset, batch_size=4, shuffle=True, num_workers=4, collate_fn=utils.collate_fn)
You must be familiar with all terms which have been used in this command from previous homework except collate_fn=utils.collate_fn.
collate_fn=utils.collate_fn is used to return the tuples of images and image annotations in every iteration.
Note: For data loader of train set use batch size of 4 and for data loader of validation set use batch size of 1.
If you use batch size of 4 for both train and validation sets, you will get CUDA out of memory error.
Note: You also need to create dataloader for train, test and validation sets separately.
- Number of categories which are in PASCAL dataset is 5. The categories are person, bicycle, car, motorcycle, airplane and their
corresponding labels are 1, 2, 3, 4, 5, respectively. In addition to these labels, label 0 belongs to category of background and as the result
the total number of classes which you need to use for training process is 6.
PennFudanPed_hw3 just contains pedestrian (person) category. As the result the total number of classes
for the object detection task is 2.
Part IV: Train Object Detection Network on Our Dataset
In this homework, we will use Faster RCNN
- Now we need to first load the model for object detection which have been pre-trained. Here is the command
to load the pre-trained model:
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
The number of classes in pre-trained model is different from the number of classes in our datasets. So similar to what you did in homework 2, you need to replace the box_predictor of
model with a new FastRCNNPredictor layer to predict 6 classes when you are training on PASCAL dataset and
2 classes when you are training on PennFudanPed_hw3 dataset.
- Before starting the training process you need to set the optimizer, scheduler and number of epochs similar to what you
did in homework 2.
Note: Since every epoch of training for this task on pascal dataset takes a long time,
do not use large value for number of epochs.
Training Phase:
- Now you can start to train the network and in every epoch you have two phases of train and validation. In every epoch,
if the mAP of the validation set is the largest mAP so far, you need to save the model weight.
- In every epoch, first you need to iterate over train set to perform the training process and then
iterate over the validation set to evaluate the performance of trained model. Here is the set of commands
to iterate over data, prepare the images and labels, and use them as input to model for object detection task:
for images, targets in data_loader:
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
loss_dict = model(images, targets)
First line in for loop: Since the images and targets are of type tuple, we need to convert them to a list. In the first line of for loop, first all Images
in the batch are transferred to GPU device and then a list is created from all images. The input to the model is
the list of all images of the batch.
Second line in for loop: A target is a dictionary which contains the bounding box of objects, label of object, image ids, the areas of bounding boxes and whether
or not the image is crowded. In the second line of for loop, all the values in dictionary of every image targets (annotations) are transferred
to GPU device and finally a list is created from all targets in the batch.
Third line in for loop: We use the the images and targets as input to the model and get the loss values.
Note that the inputs to the model in train mode are both the images and the targets (annotations).
Since the task of object detection has more than one loss value, the output for every image is a dictionary of all loss
values. The dictionary contains following loss values: 1) loss_classifier: measures the performance of the object classification for detected bounding boxes,
2) loss_box_reg: measures the performance of network for retrieving the coordinates of the ground truth bounding boxes,
3) loss_objectness: measures the performance of network for retrieving bounding boxes which contain an object
and 4) loss_rpn_box_reg: measures the performance of network for retrieving the region proposals.
- In the next step, you need to sum all losses and backpropagate the loss. Also, like homework 2, in every iteration of training phase
you need to zero the gradient and apply step function of the optimizer.
- After iterating over the whole train set, you need to update the scheduler.
Validation Phase:
- In the validation phase you need to create a coco evaluator to evaluate the performance of
the network. To create an evaluator, first you need to create a coco API from our dataset:
coco = get_coco_api_from_dataset(data_loader.dataset)
Then you need to specify the IoU type:
iou_types = ["bbox"]
At the end, you can create a coco evaluator from coco API and IoU types:
coco_evaluator = CocoEvaluator(coco, iou_types)
- At this point, you can start to iterate over validation set and compute the mAP. In every iteration
first you need to transfer the images to GPU and then use them as input to the model. The input of
model in evaluation mode is just images and as opposed to train phase, you do not
need to transfer the target (annotations) to GPU. Here is the command to get the object detection for the images:
outputs = model(image)
- For evaluation in coco_evaluator, the outputs needs to be on CPU and you need to transfer them from GPU to CPU. Then you need
to create the pair of target and output as follows:
res = {target["image_id"].item(): output for target, output in zip(targets, outputs)}
- Now the res is used to update the coco evaluator in every iteration:
coco_evaluator.update(res)
- After iterating over all images, you need to run the following commands to get the final results for evaluation in every epoch:
coco_evaluator.synchronize_between_processes()
coco_evaluator.accumulate()
coco_evaluator.summarize()
- At this point you can get the mAP over all validation set by the following command:
coco_evaluator.coco_eval['bbox'].stats[0]
You need to save the model weight which has the highest mAP on the validation set.
Part V: Experimenal Result for Object Detection on Our Datasets:
For this part, you need to follow these steps for both PASCAL and PennFudanPed_hw3 datasets:
- Train the network with different hyperparameters (we recommed you to first focus on trying different learning rates and if you have enough time,
you can also play with the number of epochs). You need to do
at least 3 different experiments with different hyperparameters.
- Report the best test and validation accuracy in all of your experiments.
- Use the model which has the best test accuracy among all of your experiments to visualize
the object detection results. For your visulization, you need to write a code to draw the bounding boxes which
have been detected by the network in the image. In addition to bounding boxes, the name of category and its score should be shown somewhere aroud
the bounding box. Your code needs to find 20 images from the test set with highest mAP, draw the bounding boxes and save in a directory. Then you need
to visulize the images in a Jupyter notebook. In your submission, you need to submit both the original notebook and its html
version.
To use Jupyter notebook on clusters there are three main ways depending on your operating system:
- CRC OnDemand interface (Same for all operating systems): You can open a Jupyter notebook from the
OnDemand CRC interface.
In the OnDemand CRC interface, you need go to interactive job tab and click on Jupyter notebook.
At the end, you need to launch the notebook by selecting the python version, number of hours and
number of cores. Note that you just can use this Jupyter to run a regular python code
and you do not have access to torch.
- Jupyter Notebook on a remote machine (Mac): The advantage of using this way to
open a Jupyter notebook is that you can get access to torch. You need to open two terminal windows.
In the first terminal, you need to connect to crc clusters, open a virtual environment without requesting
for GPU, and run the following command:
jupyter notebook --no-browser --port=8889
In the second terminal, you need to run the following command:
ssh -N -L localhost:8888:localhost:8889 your_pitt_id@h2p.crc.pitt.edu
At the end, you need to open the following link in your browser:
http://localhost:8888/
- Jupyter Notebook on a remote machine (Windows): We have explained the details of
the way Windows user can open a notebook in this link.
- Finally you need to compare the results of two datasets with each other and discuss
the possible reasons for the differences in results.
In your discussion, you need to mention at least two reasons for the differences and write a comprehensive
explanation for the reasons. To explore the differences, you can compute the statistics for the number of
samples from every class in both datasets. Also visualizing the images is helpful.
Deliverables:
- A python file to train of the network.
- A python file to test the network.
- A python file to visulize the object detetcion results.
- Two Jupyter Notebooks plus their html version to show the results of visualization for
both PASCAL and PennFudanPed_hw3 datasets.
- A report to analyze the experimenal results.
Note: If your code can not be run, you can only receive up to 50% of the grade, even if you have all the required information in your report.
Grading rubric:
- [40 points] Code for training and validation of the network.
- [10 points] Code for testing the saved model weight on the test set.
- [20 points] Visualize the object detection results.
- [30 points] Write a report of the required experiments.
Acknowledgements: This assignment was prepared for you by Narges Honarvar Nazari and partly adapted from PyTorch tutorial for object detection.
Part II has been adapted from a homework desinged by Nils Murrugarra-Llerena. The photos used for this assignment come from the PASCAL
and Penn-Fudan datasets.
 hide forever |
hide once
hide forever |
hide once