CS 2770: Homework 3
Due: 4/16/2019, 11:59pm
This assignment is different than the previous assignments in that it emphasizes experimentation and analysis, rather than implementation. It has three parts. The first one asks you to experiment with two versions of the YOLO network for object detection, and to measure the mean average precision (mAP) of the network. The second part asks you to experiment with different hyperparameters and design choices of a recurrent neural network. Most, but not all, code for these two parts is provided for you. The third part asks you to answer a set of short essay questions. Think of this as your opportunity to think broadly about the goals of computer vision, and analyze where the community stands in terms of these goals.
Part I: Object Detection with Versions of YOLO (40 points)
In this problem, you will use and evaluate two pre-trained object detectors, Standard YOLO ("You Only Look Once: Unified, Real-Time Object Detection," by Redmon et al., CVPR 2016) and Tiny YOLO. You will compute mAP scores for each, on the test set from the PASCAL VOC challenge. Tiny YOLO is faster, but less accurate than the standard YOLO model. Tiny YOLO uses mostly convolutional layers, without large fully connected layers at the end. We are going to compare both networks using mean average precision (mAP) and time predictions.
Please write code that performs the following steps. Please submit a single Python file and a single text file.
- [5 pts] Import the Darknet framework, and load the two models (for standard and tiny YOLO)
- [5 pts] Use these models to predict bounding boxes on the test set
- [5 pts] Read in the ground-truth bounding box annotations
- [15 pts] Implement the IoU (intersection over union) computation, and compute mAP (mean average precision) using the equation shown below
- [10 pts] Print the mAP and execution times for standard and tiny YOLO, and save these to a text file
Some code/scripts are provided for you on nietzsche.cs.pitt.edu in /own_files/cs2770_hw3/darknet_gpu/. (Warning: One filename contains explicit language; not our fault!) Note that because the only official release of YOLO is in Python, this part of the assignment has to be done in Python.
We reuse code from Darknet YOLO, and we create a sample executable run.sh. We also provide a script python/cs2770_darknet.py which will import the Darknet library, select GPU, specify network, and run detection. You are encouraged to examine these files and use them in your experiments.
Note that the bounding boxes YOLO detected require a post-processing step, which is provided for you with the function post_process. Darknet outputs bounding boxes in the form of (CENTER_X, CENTER_Y, WIDTH, HEIGHT), however for evaluation we require (X, Y, WIDTH, HEIGHT). cs2770_darknet.py outputs: [['person', [151.35217475891113, 47.60009002685547, 39.76028060913086, 67.713623046875]], ['person', [21.47481918334961, 21.470802307128906, 59.922386169433594, 162.10108947753906]]], which follows the structure [CLASS, BOUNDING_BOX] where BOUNDING_BOX represents the (X, Y, WIDTH, HEIGHT) information.
We will look at how well a predicted positive bounding box matches a ground-truth bounding box, and will then compute mean average precision:
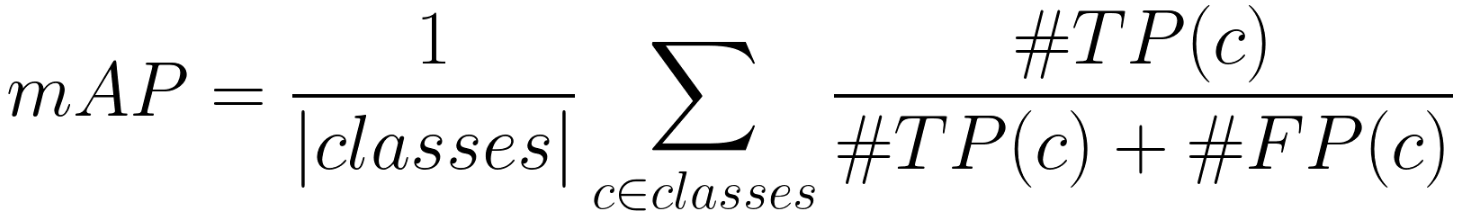 where
where
- True Positive - TP(c): a predicted bounding box (pred_bb) was made for class c, there is a ground truth bounding box (gt_bb) of class c, and IoU(pred_bb, gt_bb) >= 0.5.
- False Positive - FP(c): a pred_bb was made for class c, and there is no gt_bb of class c. Or there is a gt_bb of class c, but IoU(pred_bb, gt_bb) < 0.5.
For a given class c, to compute the Intersection over Union metric (IoU) (see image below) between any individual predicted bounding box and the ground truth bounding boxes, take the best overlap (i.e. the highest overlap between the predicted and any ground truth box) as your final score for that predicted bounding box. If there is no ground truth bounding box, but you predict a positive window, your score for that box is 0.

Test images were compiled from the PASCAL VOC dataset, and images and their correspondent bounding boxes annotations are located in:
- IMS_FOLDER=/own_files/cs2770_hw3/darknet_gpu/data_test/VOCdevkit/VOC2007/JPEGImages/
- ANNOT_FOLDER=/own_files/cs2770_hw3/darknet_gpu/data_test/VOCdevkit/VOC2007/labels/
The annotation files follow the structure: CATEGORY X Y WIDTH HEIGHT, and these are your ground truth data. In total, there are 20 categories: aeroplane, bicycle, bird, boat, bottle, bus, car, cat, chair, cow, diningtable, dog, horse, motorbike, person, pottedplant, sheep, sofa, train, tvmonitor.
You will need to retrieve all VOC classes. You can get information of all available classes in the file: /own_files/cs2770_hw3/darknet_gpu/data/voc.names. You can go over all images using glob.glob(IMS_FOLDER + '*.jpg'). To measure time for all bounding boxes predictions, you can use the time.time() function.
Part II: Recurrent Neural Networks (20 points)
In this problem, you will compare different parameter configurations for a recurrent network, using the perplexity measure (see slides 32-36 here).
We reuse code from this Tensorflow tutorial, which shows how to train a recurrent neural network on a language modeling task. Its goal is to fit a probabilistic model which assigns probabilities to sentences. It does so by predicting next words in a text given a history of previous words. Read this tutorial for background. All tutorial files are already in /own_files/cs2770_hw3/rnn/code/.
We created a sample executable run.sh for you, in the directory /own_files/cs2770_hw3/rnn/code/. Line 2 specifies which GPU to use, and Line 6 trains an RNN with the "small configuration" parameters; see line 320 in ptb_word_lm.py and the figure below. This executable takes around 20 minutes to run and the output will show perplexity measures for the train and validation data. Please copy all files from /own_files/cs2770_hw3/rnn/code/ to your own directory.
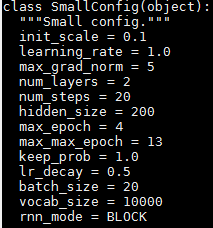
Your task it to modify the SmallConfig parameters from ptb_word_lm.py (please don't modify this file, instead create a copy of it), and analyze their contribution to performance. You are required to test three parameters: hidden_size, keep_prob and num_steps. The parameters' roles are as follows: hidden_size is the number of LSTM units in the network, keep_prob is the probability of keeping weights in the dropout layer, and num_steps is number of words that the model will learn from to predict the words coming after (for example, if num_steps=5 and the input is "The cat sat on the", the output will be "cat sat on the mat").
You need to generate train and validation perplexity curves with 8 different configurations, modifying hidden_size with (200, 400), keep_prob with (1.0, 0.5), and num_steps with (20, 30). You will then describe your findings in a separate text file.
We have marked places in ptb_word_lm.py and run.sh that need modification with TODO1, TODO2, TODO3. Some suggested steps are as follows:
- Modify the SmallConfig class from ptb_word_lm.py, and create the 8 previously mentioned configurations: c1, c2, ..., c8. Look for "TODO1" to add the new configurations.
- Update get_config from ptb_word_lm.py, so it can receive the name (c1-c8) for each of these 8 configurations by console. Look for "TODO2" to add the new configurations code.
- Update the run.sh file to run all configurations, and save the outputs in separate files. For configuration c1, the command will be:
python ptb_word_lm.py --data_path=/own_files/cs2770_hw3/rnn/simple-examples/data/ --model=c1 > c1.txt
It will save all output in c1.txt file. Look for "TODO3".
- Execute bash script: bash run.sh
- Run python create_tables.py, and it will create c1.csv, ..., c8.csv files with perplexity measures.
Please submit your modified versions of ptb_word_lm.py and run.sh, the output CSV files, along with a text file describing your conclusions: What parameters are preferable for this problem?
- [5 pts] Create 8 configurations
- [5 pts] Run scripts and output CSV files
- [10 pts] Text file with conclusions
Part III: Essay Questions (40 pts)
Please respond to the following questions with 5-10 sentences.
- [10 pts] Currently standard object detection evaluation penalizes approaches in the same way for confusing an object category with a (1) semantically related or (2) semantically unrelated category. How would you modify the mAP computation to account for semantic similarity? Can you imagine other scenarios where you might want to optimize a variant of mAP that doesn't exactly look like the mAP you computed above? What would this scenario be, and how might you modify the mAP computation to better reflect your desired outcome?
- [10 pts] There are a variety of approaches to how we can model video with neural networks. Describe two approaches that you can construct based on the content presented in class. For each method, describe some possible applications that this method would be appropriate/advantageous for, and some applications where this method might achieve poor results.
- [10 pts] The computer vision community has primarily approached object detection using static/image data. In what ways might learning about objects from video make the object modeling task easier? In what ways does video make object modeling harder? In what ways might embodied learning, where an agent can approach objects and manipulate them (e.g. turn them or shake them) offer additional advantages beyond video? What are the challenges of learning in this embodied fashion?
- [10 pts] Unsupervised learning, where we have plentiful data but it is not semantically labeled, is beneficial in that it allows us to leverage massive "free" data, without incurring a high human labeling cost. What are some ways in which we can use unlabeled data to learn about the visual world? Do you think unsupervised learning will always be upper-bounded in terms of performance by supervised learning? Why or why not?
Acknowledgement: The first two parts of this assignment were originally designed and prepared by Nils Murrugarra-Llerena.