CS 1678: Homework 3
Due: 4/8/2021, 11:59pm
This assignment is worth 50 points.
As for HW2, you will write your code and any requested responses or descriptions of your results, in a Colab Jupyter notebook.
We strongly recommend you to spend some time (1-2 hours) to read the recommended implementation and our
starter code (here), before you start on your own. Excluding the time for training the models (please leave a few days
for training), we expect this assignment to take 8-10 hours.
Part A: Implement AlexNet - Winner of ILSVRC 2012 (10 points)
AlexNet is a milestone in the resurgence of deep learning, and it
astonished the computer vision community by winning the ILSVRC 2012 by a
large margin.
In this assignment, you need to implement the original AlexNet using PyTorch.
The model architecture is shown in the following figure, which is from their original paper.
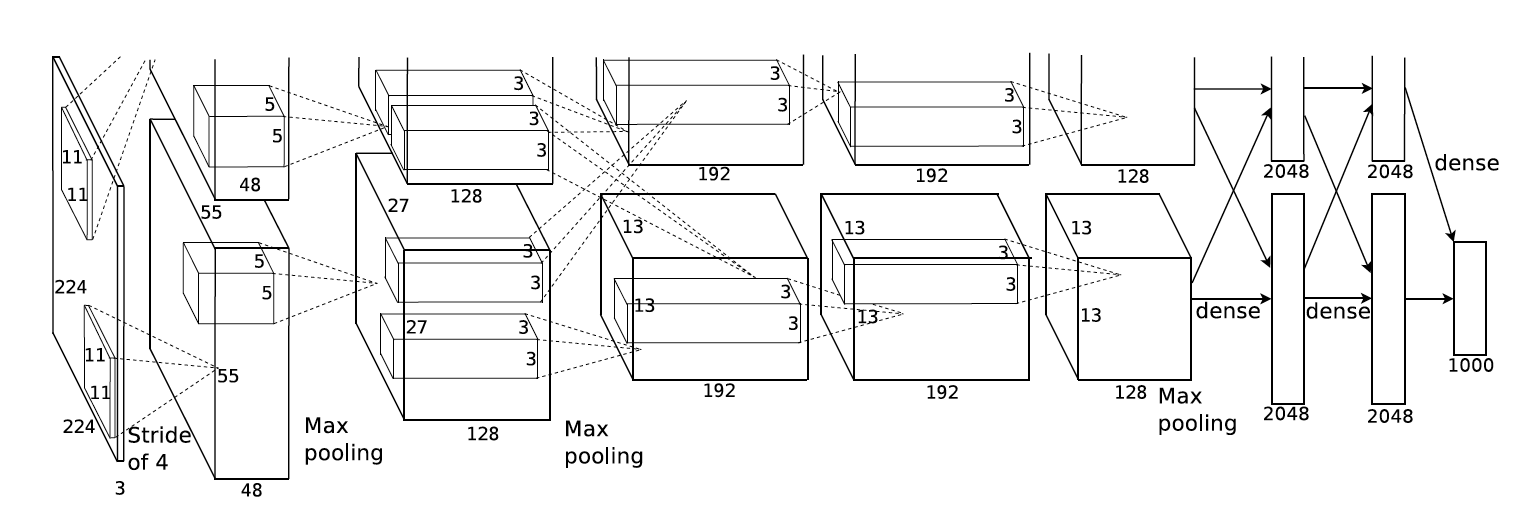
More specifically, your AlexNet should have the following architecture (e.g. for domain prediction task):
================================================================================================================
Layer (type) Kernel Padding Stride Dilation Output Shape Param #
----------------------------------------------------------------------------------------------------------------
Conv2d-1 11 x 11 4 [-1, 96, 55, 55] 34,944
ReLU-2 [-1, 96, 55, 55] 0
MaxPool2d-3 3 2 [-1, 96, 27, 27] 0
Conv2d-4 5 x 5 2 [-1, 256, 27, 27] 614,656
ReLU-5 [-1, 256, 27, 27] 0
MaxPool2d-6 3 2 [-1, 256, 13, 13] 0
Conv2d-7 3 x 3 1 [-1, 384, 13, 13] 885,120
ReLU-8 [-1, 384, 13, 13] 0
Conv2d-9 3 x 3 1 [-1, 384, 13, 13] 1,327,488
ReLU-10 [-1, 384, 13, 13] 0
Conv2d-11 3 x 3 1 [-1, 256, 13, 13] 884,992
ReLU-12 [-1, 256, 13, 13] 0
MaxPool2d-13 3 2 [-1, 256, 6, 6] 0
Flatten-14 [-1, 9216] 0
Dropout-15 [-1, 9216] 0
Linear-16 [-1, 4096] 37,752,832
ReLU-17 [-1, 4096] 0
Dropout-18 [-1, 4096] 0
Linear-19 [-1, 4096] 16,781,312
ReLU-20 [-1, 4096] 0
Linear-21 [-1, 4] 16,388
================================================================================================================
Note: The `-1` in Output shape represents `batch_size`, which is flexible during program execution.
Before you get started, we have several hints hopefully to make your life easier:
Instructions:
- Download the starter code, which includes data, from Canvas, and put the starter code in a Colab notebook.
-
Complete the implementation of class AlexNet, and training the model for domain prediction task.
A sample usage for the provided training/evaluation script (from the shell) is
python cnn_trainer.py --task_type=training --label_type=domain --learning_rate=0.001 --batch_size=128 --experiment_name=demo
- You may need to tune the hyperparamters to achieve better performance.
- Report the model architecture (i.e. call print(model) and copy/paste the output in your notebook), as well as the accuracy on the validation set.
Part B: Visualizing Learned Filters (10 points)
Different from hand-crafted features, the convolutional neural network
extracted features from input images automatically thus are difficult
for human to interpret. A useful strategy is to visualize the kernels
learned from data. In this part, you are asked to check the kernels
learned in AlexNet for two different tasks, i.e. classifying domains or classes.
You need to compare the kernels in different layers for two models
(trained for two different tasks), and see if the kernels have different
patterns.
For your convenience, we provided a visualization function in the starter code (visualize_kernels).
Instructions:
- Train two AlexNet on the PACS dataset for two different tasks (predicting domain and predicting class, respectively) using the same, optimal hyperparameters from Part A.
- Complete a function named analyze_model_kernels,
which: (1) load the well-trained checkpoint, (2) get the model kernels
from the checkpoint, (3) using the provided visualization helper
function visualize_kernels to inspect the learned filters.
- Report the kernel visualization for two models, and 5
convolution kernels for each model, in your notebook. Compare the learned
kernels and summarize your findings.
Part C: Sentiment analysis on IMDB reviews (15 points)
Large Moview Review Dataset (IMDB) is a dataset for binary sentiment
classification containing substantially more data than previous
benchmark datasets.
It provides a set of 50,000 highly polar movie reviews. We have split
the dataset into training (45,000) and test (5,000). The
positive:negative ratio is 1:1 in both splits.
In this task, you need to develop a RNN model to "read" each review then predict whether it's positive or negative.
In the provided starter code, we implemented a RNN pipeline (sentiment_analysis.py) and a GRUCell (rnn_modules.py) as an example.
You need to build a few other variants of RNN modules, specifically as explained in this blog.
Please see this link for a Colab version of the starter code which you can use in your own Colab notebook.
You are not allowed to use the native torch.nn.LSTMCell or other built-in RNN modules in this assignment.
Instructions:
- Read the code in rnn_datasets.py and sentiment_analysis.py,
then run the training with provided GRU cell. You should be able to
achieve at least 85% accuracy in 50 epochs with default hyperparameters.
Attach the figures (either TensorBoard screenshot or plot on your
own) of (1) training loss, (2) training accuracy per epoch and (3)
validation accuracy per epoch in your report.
- Implement the following variant in rnn_modules.py, details in the blog, the section named Variants on Long Short Term Memory.
LSTMCell: classical LSTM with input gate and forget gate, also cell state and hidden state.
Please note that the class is already provided for you, and you only need to complete the __init__ and forward functions. Please do NOT change the signatures.
- Print number of model parameters for different module type (
GRUCell and LSTMCell) using count_parameters, and include the comparison in your notebook.
Use the following hyperparameters for comparison: input_size=128, hidden_size=100, bias=True.
- Run experiments with your custom implementation on
sentiment analysis with IMDB dataset, and compare the results with the
GRU, including both speed and performance.
Attach the training loss and training/validation accuracy plot.
Part D: Building a Shakespeare writer (15 points)
RNN has demonstrated great potential in modeling language, and one
interesting property is that it can "learn" to generate new sentences.
In this task, you need to develop a character-based RNN model (meaning
instead of words, RNN processed one character at a time) to learn how
to write like Shakespeare.
Instructions:
- Read the code in rnn_datasets.py and sentence_generation.py, and complete the
SentenceGeneration class which is a character-level RNN.
You can reuse (by copy/paste) most of the codes from SentimentClassification
in Part C, just note that instead of predicting positive or negative,
now your task is to predict the next character given a sequence of chars
(history).
- Train the model with the GRU module on Shakespeare books.
You should be able to achieve loss value of 1.2 in 10 epochs with
default hyperparameters. You probably need to use an embedding_dim of 256 and hidden_size of 512 to get the above loss value. If you are interested you could try with your own LSTM variant, but experiments with GRU is required.
- Complete the function in sentence_generation.py to load your trained model and generate new sentence from it.
Basically, once a language model is trained, it is able to predict
the next character after a sequence, and this process can be continued
(predicted character serve as history for predicting the next).
More specifically, your model should be able to predict the
probability distribution over the vocabulary for the next character, and
we have implemented a sampler sample_next_char_id which
samples according to the probability. By repeating this process, your
model is able to write arbitrarily long paragraphs.
For example the following passage is written by a GRU trained on Shakespeare:
ROMEO:Will't Marcius Coriolanus and envy of smelling!
DUKE VINCENTIO:
He seems muster in the shepherd's bloody winds;
Which any hand and my folder sea fast,
Last vantage doth be willing forth to have.
Sirraher comest that opposite too?
JULIET:
Are there incensed to my feet relation!
Down with mad appelate bargage! troubled
My brains loved and swifter than edwards:
Or, hency, thy fair bridging courseconce,
Or else had slept a traitors in mine own.
Look, Which canst thou have no thought appear.
ROMEO:
Give me them: for that I put us empty.
RIVERS:
The shadow doth not live: and he would not
From thee for his that office past confusion
Is their great expecteth on the wheek;
But not the noble fathom were an poison
Here come to make a dukedom: therefore--
But O, God grant! for Signior HERY
VI:
Soft love, that Lord Angelo: then blaze me all;
And slept not without a Calivan Us.
Note that the model learns how to spell each word and write the
sentence-like paragraphs all by itself, even including the punctuations
and line breaks.
Please use ROMEO and JULIET as history to begin the generation for 1000 characters each, and attach the generated text.
Submission: Please submit your Jupyter notebook with the classes and functions from all Python files in the startup zip file:
- classes and functions from cnn_trainer.py
- classes and functions from rnn_datasets.py
- classes and functions from sentence_generation.py
- classes and functions from sentiment_analysis.py
- classes and functions from rnn_modules.py
Acknowledgement: This assignment was designed by Mingda Zhang in Spring 2020 for CS1699: Intro to Deep Learning.