CS 1678: Homework 4
Due: 11/8/2021, 11:59pm
This assignment is worth 30 points.
As for HW3, you will write your code and any requested responses or descriptions of your results, in a Colab Jupyter notebook.
We strongly recommend you to spend some time (1-2 hours) to read the recommended implementation and our
starter code (here), before you start on your own. Excluding the time for training the models (please leave a few days
for training), we expect this assignment to take 4-6 hours.
Part A: Implement AlexNet - Winner of ILSVRC 2012 (10 points)
AlexNet is a milestone in the resurgence of deep learning, and it
astonished the computer vision community by winning the ILSVRC 2012 by a
large margin.
In this assignment, you need to implement the original AlexNet using PyTorch.
The model architecture is shown in the following figure, which is from their original paper.
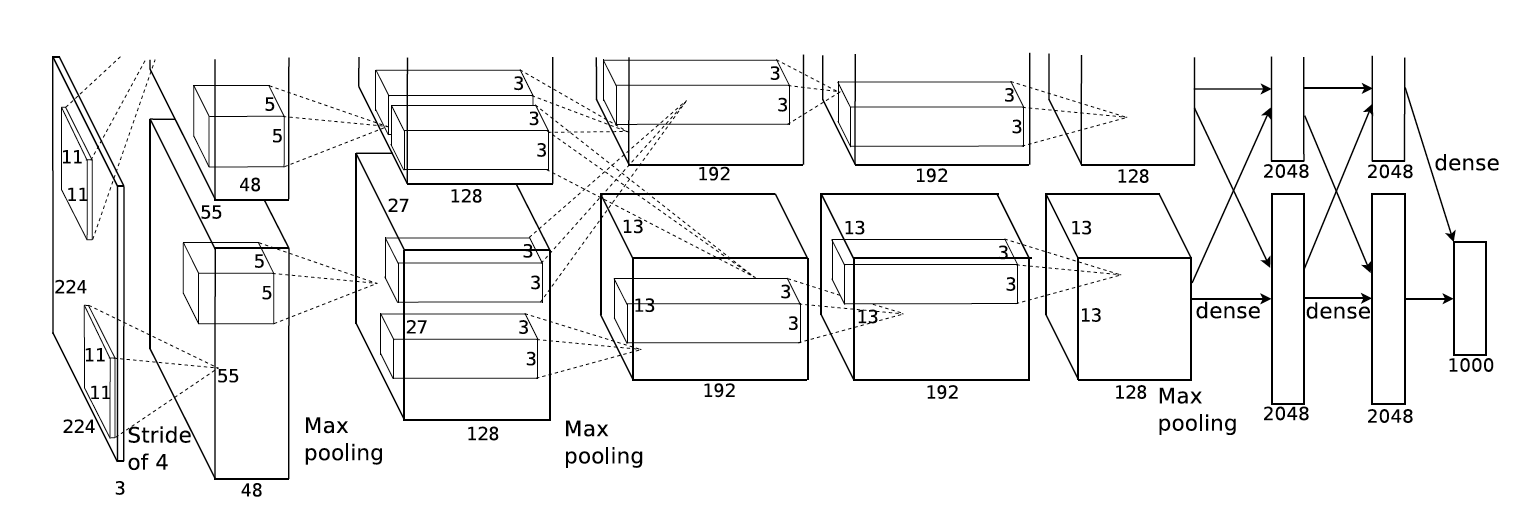
More specifically, your AlexNet should have the following architecture (e.g. for domain prediction task):
================================================================================================================
Layer (type) Kernel Padding Stride Dilation Output Shape Param #
----------------------------------------------------------------------------------------------------------------
Conv2d-1 11 x 11 4 [-1, 96, 55, 55] 34,944
ReLU-2 [-1, 96, 55, 55] 0
MaxPool2d-3 3 2 [-1, 96, 27, 27] 0
Conv2d-4 5 x 5 2 [-1, 256, 27, 27] 614,656
ReLU-5 [-1, 256, 27, 27] 0
MaxPool2d-6 3 2 [-1, 256, 13, 13] 0
Conv2d-7 3 x 3 1 [-1, 384, 13, 13] 885,120
ReLU-8 [-1, 384, 13, 13] 0
Conv2d-9 3 x 3 1 [-1, 384, 13, 13] 1,327,488
ReLU-10 [-1, 384, 13, 13] 0
Conv2d-11 3 x 3 1 [-1, 256, 13, 13] 884,992
ReLU-12 [-1, 256, 13, 13] 0
MaxPool2d-13 3 2 [-1, 256, 6, 6] 0
Flatten-14 [-1, 9216] 0
Dropout-15 [-1, 9216] 0
Linear-16 [-1, 4096] 37,752,832
ReLU-17 [-1, 4096] 0
Dropout-18 [-1, 4096] 0
Linear-19 [-1, 4096] 16,781,312
ReLU-20 [-1, 4096] 0
Linear-21 [-1, 4] 16,388
================================================================================================================
Note: The `-1` in Output shape represents `batch_size`, which is flexible during program execution.
Before you get started, we have several hints hopefully to make your life easier:
Instructions:
- Download the starter code, which includes data, from Canvas, and put the starter code in a Colab notebook.
-
Complete the implementation of class AlexNet, and training the model for domain prediction task.
A sample usage for the provided training/evaluation script (from the shell) is
python cnn_trainer.py --task_type=training --label_type=domain --learning_rate=0.001 --batch_size=128 --experiment_name=demo
- You may need to tune the hyperparamters to achieve better performance.
- Report the model architecture (i.e. call print(model) and copy/paste the output in your notebook), as well as the accuracy on the validation set.
Part B: Enhancing AlexNet (10 points)
In this part, you need to modify the AlexNet in previous part, and train different models with the following changes.
Just a friendly reminder, if you implemented AlexNet following our recommendation, it should be very easy (e.g. just changing a few lines) to perform the following modifications.
Instructions:
- Larger kernel size
Initial AlexNet has 5 convolutional kernels as defined in the table in Part A.
We observe that for the 1st, 2nd and 5th convolutional layers, a MaxPool2d layer is followed to downsample the inputs.
An alternative strategy is to use larger convolutional kernel (thus
larger receptive field) and larger stride, which gives smaller output
directly.
Please copy your AlexNet to a new class named AlexNetLargeKernel, and implement the model following the architectures given below.
class AlexNetLargeKernel
================================================================================================================
Layer (type) Kernel Padding Stride Dilation Output Shape Param #
----------------------------------------------------------------------------------------------------------------
Conv2d-1 21 x 21 1 8 [-1, 96, 27, 27] 127,104
ReLU-2 [-1, 96, 27, 27] 0
Conv2d-3 7 x 7 2 2 [-1, 256, 13, 13] 1,204,480
ReLU-4 [-1, 256, 13, 13] 0
Conv2d-5 3 x 3 1 [-1, 384, 13, 13] 885,120
ReLU-6 [-1, 384, 13, 13] 0
Conv2d-7 3 x 3 1 [-1, 384, 13, 13] 1,327,488
ReLU-8 [-1, 384, 13, 13] 0
Conv2d-9 3 x 3 2 [-1, 256, 6, 6] 884,992
ReLU-10 [-1, 256, 6, 6] 0
Flatten-11 [-1, 9216] 0
Dropout-12 [-1, 9216] 0
Linear-13 [-1, 4096] 37,752,832
ReLU-14 [-1, 4096] 0
Dropout-15 [-1, 4096] 0
Linear-16 [-1, 4096] 16,781,312
ReLU-17 [-1, 4096] 0
Linear-18 [-1, 4] 16,388
================================================================================================================
Please use the same optimal hyperparameter with Part A to train the
new model, and report architecture and accuracy in your report.
- Pooling strategies
Another tweak to the AlexNet is the pooling layer. Instead of MaxPool2d another common pooling strategy is AvgPool2d, i.e. to average all the neurons in the receptive field.
Please copy your AlexNet to a new class named AlexNetAvgPooling, and implement the model following the architectures given below.
class AlexNetAvgPooling
================================================================================================================
Layer (type) Kernel Padding Stride Dilation Output Shape Param #
----------------------------------------------------------------------------------------------------------------
Conv2d-1 11 x 11 4 [-1, 96, 55, 55] 34,944
ReLU-2 [-1, 96, 55, 55] 0
AvgPool2d-3 3 2 [-1, 96, 27, 27] 0
Conv2d-4 5 x 5 2 [-1, 256, 27, 27] 614,656
ReLU-5 [-1, 256, 27, 27] 0
AvgPool2d-6 3 2 [-1, 256, 13, 13] 0
Conv2d-7 3 x 3 1 [-1, 384, 13, 13] 885,120
ReLU-8 [-1, 384, 13, 13] 0
Conv2d-9 3 x 3 1 [-1, 384, 13, 13] 1,327,488
ReLU-10 [-1, 384, 13, 13] 0
Conv2d-11 3 x 3 1 [-1, 256, 13, 13] 884,992
ReLU-12 [-1, 256, 13, 13] 0
AvgPool2d-13 3 2 [-1, 256, 6, 6] 0
Flatten-14 [-1, 9216] 0
Dropout-15 [-1, 9216] 0
Linear-16 [-1, 4096] 37,752,832
ReLU-17 [-1, 4096] 0
Dropout-18 [-1, 4096] 0
Linear-19 [-1, 4096] 16,781,312
ReLU-20 [-1, 4096] 0
Linear-21 [-1, 4] 16,388
================================================================================================================
Please use the same optimal hyperparameter with Part A to train the
new model, and report architecture and accuracy in a text snippet in your notebook.
Part C: Visualizing Learned Filters (10 points)
Different from hand-crafted features, the convolutional neural network
extracted features from input images automatically thus are difficult
for human to interpret. A useful strategy is to visualize the kernels
learned from data. In this part, you are asked to check the kernels
learned in AlexNet for two different tasks, i.e. classifying domains or classes.
You need to compare the kernels in different layers for two models
(trained for two different tasks), and see if the kernels have different
patterns.
For your convenience, we provided a visualization function in the starter code (visualize_kernels).
Instructions:
- Train two AlexNet on the PACS dataset for two different tasks (predicting domain and predicting class, respectively) using the same, optimal hyperparameters from Part A.
- Complete a function named analyze_model_kernels,
which: (1) load the well-trained checkpoint, (2) get the model kernels
from the checkpoint, (3) using the provided visualization helper
function visualize_kernels to inspect the learned filters.
- Report the kernel visualization for two models, and 5
convolution kernels for each model, in your notebook. Compare the learned
kernels and summarize your findings.
Submission: Please submit your Jupyter notebook with the classes and functions from all Python files in the startup zip file:
- classes and functions from cnn_trainer.py
Acknowledgement: This assignment was designed by Mingda Zhang in Spring 2020 for CS1699: Intro to Deep Learning.