In lecture we discussed hashing and hashing functions. Your assignment will be to write you own, completely original, hashing function without any assistance from people or the web. The idea is simple. Design a loop that uses every char in the string to produce an integer that is unique to every string. That integer then determines where the key is stored into an array. Ideally, any 2 strings that are not ! .equals() to each other should hash to a different integer value. In practice this is impossible - at least no one knows a perfect hashing function that does not blow up on even small string lengths. As a result the best we can do is write a function that distributes the keys uniformly over a limited number of integers. An example of an optimal function is a follows: You have 1 million keys to hash, they map to into a range of array indices [0..999,9999] and there are exactly 10 words per integer in array[1..999,99990]. In this case we say the array has 100,000 buckets and each bucket has the same number of keys: 10. The hash function has done the best possible job of distributing K keys into N buckets since each bucket contains K/N keys. this is perfect/ideal hasing function because it divided up the keys perfectly into the buckets.
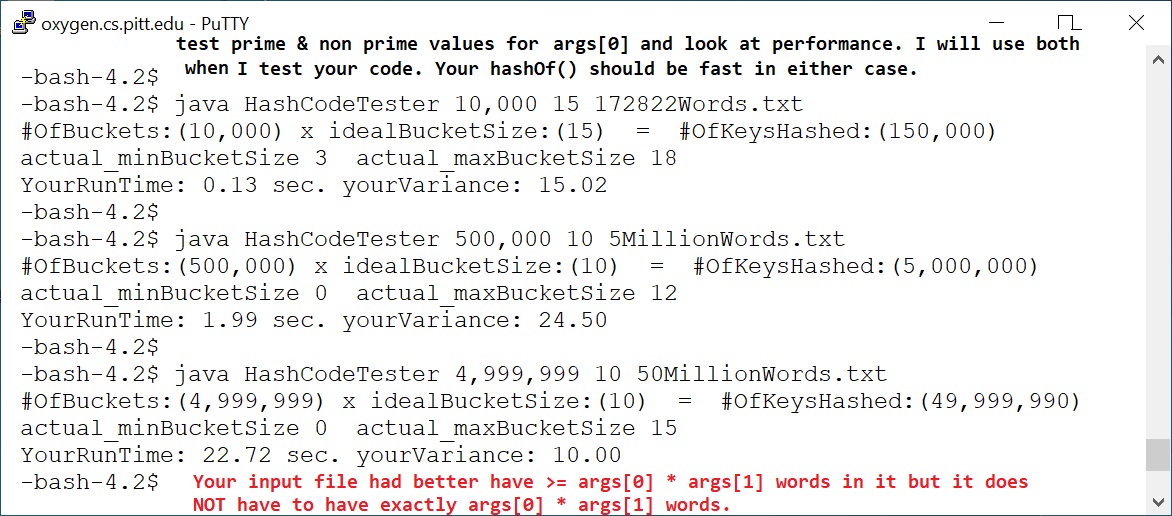
Execute your Tester using this pattern: java HashCodeTester 10,000 15 172822Words.txt
Depending on the numbers you enter, the tester might not need to read all the keys from the file. That's OK.
In the above sample execution the tester defines a MyHashCode object then calls .add() 10,000 x 15 times. The hash set object does not actually store the keys, it just increments the counters for each bucket. After the hashing is done, some stats are printed which indicate how evenly the keys were distributed among the buckets.