
CHAPTER 4 ABSTRACT DATA TYPES
Timothy Arndt, Cleveland State University, USA (arndt@cis.csuohio.edu)
Chapter Outline
4.1 Introduction to Abstract Data Types
4.2 Abstract Data Types and Object-Oriented Languages
4.3 Packages
4.4 Generic Abstract Data Types
4.5 Software Design with Abstract Data Types
4.6 Conclusions
Exercises
4.1 Introduction to Abstract Data Types
When programming large systems, one of the most important objectives of programmers
is to understand how the various components of the system work. This is a difficult task
since in these large systems programming is done by teams of programmers rather than
by a single individual. So if we want to use, for example, a data structure designed by
someone else, we first have to understand how the data structure works. Fortunately, with
a little extra work we can design the data structure in such a way that it is easy to
understand. In particular, we can use the principle of data abstraction to enhance
understandability. Abstraction allows us to consider the high-level characteristics of
something without getting bogged down in the details. Process abstraction, for example,
is supported in most modern programming languages through the various types of
subprograms (functions, procedures, etc.). This process abstraction allows one to ignore
the details of portions of a large program. Besides the ability to ignore these details it is
also useful to be able to assign portions of a large program to different teams of
programmers and to allow these programmers to work independently. In order to support
this type of division of labor, it is necessary to be able to compile only the portion of the
program that one particular team is working on. In other words, it is necessary to support
separate compilation. In C, files can be separately compiled. Languages such as Ada and
FORTRAN 90 support separately compilable modules.
Data abstraction allows us to design and use a data structure without considering how it
is implemented. This is an extremely effective approach for controlling complexity. In
particular, an abstract data type (ADT) is defined in terms of the operations that can be
performed on instances of the type rather than by how those operations are actually
implemented. In other words, an ADT defines the interface of the objects. The operations
are performed on some data that is also a part of an object of a given type.
As an example of an abstract data type, consider a check book ADT. The data type is
defined by the operations we can perform on it, e.g., add a transaction; search for a
transaction; delete a transaction; list transactions, etc. We say nothing about the
implementation of the check book. This allows us to ignore the (unimportant) details to
concentrate on the (important) overall behavior and support modular design since we can
CHECK BOOK
Figure 4.1 A Checkbook ADT
Add transaction
Search transaction
Delete transaction
List transactions
change the implementation without affecting how other modules which use this ADT will
work.
ADTs are not a part of a particular programming language (even though it is possible to
consider built-in data types like integers or characters as ADTs); rather they are
implemented by a programmer to solve a particular problem or some class of problems.
On the other hand, some programming languages offer features that can be used to easily
implement ADTs. In object-oriented languages like Java and C++, ADTs can be easily
implemented as classes. In this approach, both the operations and data of the ADT are
encapsulated in a class. In modular languages like C, ADTs can be implemented as
libraries of datatypes and functions that manipulate those data types. In this second
approach, the operations and data are defined separately, but they are grouped together in
a library so that they seem to be part of a single entity to other programmers. In this
chapter we will give examples in several programming languages to give an idea of how
different languages support ADTs.
As an example, the header file for a library implementing a simple set ADT including the
usual set operations of union, intersection and difference is given below. The
implementations of the functions would be provided in a separate source code file that
would be compiled into an object file or a static or dynamic library. The header file
would be visible to users of the ADT, but the implementation would be hidden since the
code would be compiled.
/* File set_adt.h */
#define MAX_SET_SIZE
100
#define SET_ELEMENT_TYPE
float
typedef struct SET {
SET_ELEMENT_TYPE elements[MAX_SET_SIZE];
int current_elements;
int current_position;
} set_type;
/* Prototypes
**
initialize_set must be called before any of the other
**
operations. Each of the operations has a return value
**
an error code – 0 means the operation failed, 1 means
**
it succeeded. The operation set_get_next element can
**
be used along with get_set_size to retrieve all of
**
the elements of the set. After n elements of an set of
**
size n have been retieved, the 1st element is retrieved
**
again.
*/
int set_add (*set_type set, SET_ELEMENT_TYPE element_to_add);
int set_remove (*set_type set, SET_ELEMENT_TYPE element_to_remove);
int get_set_size (*set_type set);
int set_union (*set_type set1, *set_type set2, *set_type result_set);
int set_intersect (*set_type set1, *set_type set2,
*set_type result_set);
int set_difference (*set_type set1, *set_type set2,
*set_type result_set);
int set_get_next_element (*set_type set1, SET_ELEMENT_TYPE retrieved);
int initialize_set (*set_type set);
Other programs can now use this library by including the header file and then linking the
library. The following program fragment illustrates this use.
/* File client.c */

#include “set_adt.h”
. . .
set_type my_set;
. . .
/* Initialize and use a set */
result = initialize_set(&my_set);
result = set_add(&my_set, 7.0);
printf(“The size of my_set is %d\”, get_set_size(&my_set);
. . .
Now we can see the utility of using ADTs when working on a large project. Rather than
having to understand the detailed implementation of the set operations, the user only has
to study the interface – the abstraction is at a much higher level so much time can be
saved. There are other advantages to using ADTs as well. When the ADT can be used in
a variety of different programs (as in our set example), we achieve the highly desired goal
of software reuse. It is more cost effective for organizations to use existing, well-tested
components in large projects than it is to write the component from scratch. One of the
reasons that reuse isn’t more widespread is the difficulty in understanding legacy code
written by another programmer. ADTs avoid this problem by hiding the implementation.
This points still another advantage of ADTS –
information hiding. The reason that
information hiding is generally desirable is because it makes code more modular. This
allows the implementation of the component to be changed without affecting some other
component. Since the implementation is hidden, we can’t base our code on that
implementation (which could cause our code to break if the implementation is changed).
On the other hand, it is critical that the interface not change. The interface is considered a
kind of contract between the implementers and the users of the ADT.
Figure 4.2 An Abstract Data Type
Figure 4.2 shows another view of an abstract data type. It presents an interface to the
world that consists of a number of operations that can be performed on the data structure
encapsulated by the ADT. The data structure itself is not visible to the outside world.
When the ADT makes its interface visible, it is said to export the interface. The hiding of
the data structure inside the ADT is referred to as encapsulation and it is the means by
which we accomplish the desired information hiding.
4.2 Abstract Data Types and Object-Oriented Languages
Earlier we stated that object-oriented languages like C++ and Java make implementing
ADTs easy by providing the class construct. The reader may be wondering what exactly
the relation between ADTs and object-orientation as a programming language paradigm
is and what differences, if any, exist between the two concepts. In this section we will
Interface - Operations
Data Structure
explore these questions.
One type of operator often provided as part of an ADT is called a constructor. It creates a
new instance of the ADT. In object-oriented languages, the ADT is modeled by a class,
while the instance is called an object. A constructor operation is provided for each class
of objects and a destructor operator that destroys the object is provided for each class as
well. Objects, in this programming paradigm, are dynamically created and destroyed. As
we saw in the sets example from the previous section, this is not necessarily the case
when using ADTs in a non object-oriented language. Notice that there is no constructor
function provided as part of the ADT, instead the instance of the ADT is declared as
being of the ADT type, and an initialization operation is provided.
Objects are sometimes said to communicate by exchanging messages in the object-
oriented paradigm. In practice, this usually boils down to having a message cause one of
the operations of the object to be executed. The operations in turn are usually referred to
as methods. The data structures of the objects are called properties.
One large addition to the ADT idea in object-oriented languages is inheritance.
Inheritance allows us to define one class of objects as a subclass of another, previously
existing class. The subclass is then said to inherit from the superclass. What this means is
that the newly defined class has all of the same methods (operations) and properties (data
structures) as the superclass. New operations and properties can be added to the subclass
and existing methods can be replaced (overridden) as well. Subclassing allows existing
classes to be specialized, thus supporting software reuse. A simple example is the use of a
preexisting shape class to define new rectangle and triangle classes. We would subclass
the shape class to produce new rectangle and triangle classes, adding new methods such
as get_area and get_perimeter, while reusing methods such as get_color, set_color,
get_line_width, and set_line_width. Some object-oriented languages (e.g. C++) allow a
class to inherit from more than one superclass while others (e.g. Java) do not. This
capability is called multiple inheritance. Inheritance is such a fundamental property of
object-oriented languages that languages such as the early versions of Ada which support
ADTs but not inheritance are sometimes referred to as object-based rather than object-
oriented.
One further feature supported by some object-oriented languages like Smalltalk is run-
time binding or polymorphism. This allows the determination of the class of an object in
a program to be put off until the program runs, allowing for a very flexible programming
style. Other object-oriented languages like C++ require the class of an object (or the most
general class an object can belong to) to be specified when the program is written. This is
known as compile-time binding.
The C++ header file corresponding to the previous set ADT is shown below.
//**********************************************
//
// File set_adt.h
//
//**********************************************
#define MAX_SET_SIZE
100
#define SET_ELEMENT_TYPE
float
class Set
{
public:
bool is_full () const;
// Postcondition:
//
Return value is true if list is full
//
false otherwise
bool is_empty () const;
// Postcondition:
//
Return value is true if list is empty
//
false otherwise;
int set_add (SET_ELEMENT_TYPE element_to_add);
// Precondition:
//
NOT is_full() and element_to_add has a value
// Postcondition:
//
element_to_add is in Set and get_set_size() ==
//
get_set_size()@entry + 1
int set_remove (SET_ELEMENT_TYPE element_to_remove);
// Precondition:
//
NOT is_empty()
// Postcondition:
//
If element_to_remove is in set @entry
//
element_to_remove is no longer in set
//
and get_set_size() == get_set_size()@entry - 1
int get_set_size () const;
int set_union (Set& set2, Set& result_set) const;
int set_intersect (Set& set2, Set& result_set) const;
int set_difference (Set& set2, Set& result_set) const;
int set_get_next_element (SET_ELEMENT_TYPE retrieved);
Set(); // Constructor
~Set(); // Destructor
private:
SET_ELEMENT_TYPE elements[MAX_SET_SIZE];
int current_elements;
int current_position;
};
We can make several interesting observations about the C++ code. Notice first of all that
the class construct incorporates both the data structures that implement a set as well as
the functions (methods) that manipulate these data structures. By declaring the data
structures as private, we specifically prevent the manipulation of these data structures by
any means other than the public methods of the class. These methods are made available
to other objects by declaring them in the public section. Among the public methods are a
contructor method which creates a new instance of the class (allocating the necessary
memory) and a destructor method that destroys an instance (deallocating the object’s
memory).
Another interesting point regards the use of preconditions and postconditions in the
documentation of the methods. These represent a kind of contract between the
implementers and the users of the methods. If the condition specified in the precondition
holds when the method is invoked, then the postcondition is guaranteed to hold when the
method completes. This type of standard documentation makes it easier to understand the
methods.
Finally, the const keyword specifies that the method so tagged does not modify the data
values of the object when it is executed. The use of this tag can make understanding the
code easier for programmers who didn’t write the code.
The relationship between ADTs and object-oriented languages is summarized in the
following figure.

Figure 4.3 Object-Oriented Languages and ADTs
4.3 Packages
We have seen in the previous section that classes provide a natural way to implement
ADTs. Another programming language structure that is widely used for this purpose is
the package. A package actually has two important features. First of all it can be used for
partitioning a program or for the construction of reusable units. Part of this partitioning
might also include the ability to partition the namespace of a program.
In very large programs with many libraries of classes, functions, procedures, variables,
constants, etc., it is quite possible that one of these entities that we define in our program
can have the same name as an entity defined in a library (or somewhere else in the
program). This can be a very difficult problem to understand since we have to keep in
mind the definitions for all of the entities defined in all of the libraries that our program
uses. In languages that use packages to partition the namespace, we must explicitly
import the package to make the classes, functions, etc. of the package usable. All the
other entities in packages that we do not explicitly import are invisible. In other words,
the classes, constants, etc. are hidden from us so we can give one of our entities the same
name and no confusion will result – ours is the only visible entity with that name, so any
reference to that name refers to the entity we have defined. We will explore this use of
packages later using Java as our example language.
The second use of packages is as an encapsulation mechanism. Some languages (e.g.
Ada) use the package as the basic encapsulation mechanism. In object-oriented languages
like Java which support packages the package is a more general encapsulation
mechanism than classes and may include classes in the package.
Ada packages are the basic unit for both encapsulation and reuse. Packages have two
parts (stored in two different files) – the package specification and the package body. The
package specification contains the interface of the package while the package body
contains the implementation of the functions and procedures contained in the package.
Generally, only the package specification is available (visible) to users of the package.
The package may contain functions, procedures (the difference between procedures and
functions is that functions return a value while procedures do not. In C all subprograms
are functions, but the return value can be ignored – it doesn’t need to be used in an
expression), data structures, constants, etc. Packages have two parts – public and private.
The entities declared in the public part of the package are available to all users of the
package while only the functions and procedures of the package may use the entities in
the private part of the package. The first part of the package is the public part while the
keyword private starts the private part. In order to achieve our information-hiding goal,
we usually declare only the ADTs operations in the public part of the package while the
implementation of the ADT (its data structure) is declared in the private part.
It may seem counterintuitive to make the implementation visible to users of the package
by including it in the private part of the package specification. If our goal is information-
hiding why not leave it out of the package specification altogether? The reason is so that
ADTs - Classes
Inheritance
Run-Time Binding
the package body need not be available at compilation time. In order to compile the
program that uses the package the compiler needs information about the implementation
of the ADT. This information is available in the private part of the package specification.
Modula-2 handles this problem by requiring that all ADTs whose representation is hidden
in a module (package) be pointers. This hides the implementation of the ADT from its
users, but it raises new problems of security.
An Ada package is used inside of a program by importing it via the with keyword at the
beginning of the file containing the program. This makes the package visible in the
program. In order to use the operations (functions and procedures) as well as the data
structures (variables, constants, etc.) of the package, the operations and data structures are
prefixed with the package name followed by a ‘.’ operator. If we want to avoid giving the
package name in (for example) they names of the procedures in the package we can do
this with the use keyword. This assumes that we don’t have conflicting entity names in
our program.
It is important to notice that, in general, an Ada package represents a single object (e.g. a
single set). To avoid this limitation (i.e. to define multiple sets for use in a program) we
can use the new operator inside of a program. We simply create a duplicate of the original
package creating in the process (e.g.) another set. The use of the new operator is
necessary when we have a parameterized package (as we do in the example given below).
Consider an Ada package for a set containing integers. In Ada, the integer type is called
natural. We can parameterize the package so that the user can provide the maximum
number of elements that can be contained in the set.
The Ada package specification for the set of naturals package is given below.
-- Set package specification
-- Element type: Natural numbers
-- Constraints: 0 <= get_set_size <= max_set_size
package natural_set_package is
type set(max_set_size
: positive) is limited private;
set_full
:exception;
set_empty
:exception;
function is_full (the_set : stack) return boolean;
-- Return value is true if list is full, false otherwise
function is_empty (the_set : stack) return boolean;
-- Return value is true if list is empty, false otherwise
procedure set_add (the_set : in out stack; element : natural);
-- element is added to the set
-- exceptions: set_full is raised if number of elements in the
-- set = max_set_size.
procedure set_remove (the_set : in out stack; element : natural);
-- If element is a member of the set, it is removed.
-- exceptions: set_empty is raised if number of elements in the
-- set = 0.
function get_set_size (the_set : set) return natural;
-- The size of the set is returned.
function set_union (first, second : set) return set;
-- Returns the union of the first and second sets.
function set_intersect (first, second : set) return set;
-- Returns the intersection of the first and second sets.
function set_difference (first, second : set) return set;
-- Returns the difference of the first and second sets.
function set_get_next_element (the_set : set) returns natural;
-- Returns the next set element.
private
type array_of_elements is array(positive range <>) of natural;
type set(max_set_size : positive) is record
current_elements
:natural := 0;
current_position
:natural := 1;
elements
:array_of_elements(1..max_set_size);
end record;
end natural_set_package;
The package body corresponding to the set of naturals package specification is given
below (in part).
package_body natural_set_package is
function is_full (the_set : set) return boolean is
begin
if the_set.current_elements = max_set_size then
return true;
else
return false;
end is_full;
function is_empty (the_set : set) return boolean is
begin
if the_set.current_elements = 0 then
return true;
else
return false;
end is_empty;
procedure set_add (the_set : in out stack; element : natural) is
begin
the_set.elements(current_elements + 1) := element;
the_set.current_elements := the_set.current_elements + 1;
exception
when contraint_error => raise set_full;
end set_add;
. . .
end natural_set_package;
This package could then be used as follows.
with natural_set_package;
procedure main_program is
package my_natural_set_package is new
natural_set_package(100);
. . .
my_natural_set_package.set_add(my_natural_set_package.set, 100);
Another example of the use of packages is provided by Java. As in Ada, Java packages
provide a way to group together logically related subprograms (classes in the case of
Java). Unlike in Java, packages usually consist of multiple files, rather than a single file.
This reflects the Java paradigm of one (public) class per file.
A class is defined to be part of a file by including a line of the following type at the
beginning of a file, before the class defined in the file.
package com.widgets.smallwidgets;
public class Firstsmallwidget extends Object {
. . .
This defines the class firstsmallwidget to be part of the package
com.widgets.smallwidgets. Similar declarations would appear in every other file
containing a class for this package.
The name of the package reflects an attempt to supply a unique name for every package.
The name starts with the Internet domain name of the furnisher of the package (in this
case widgets.com) in reverse order. We can add further modifiers to the name started in
this manner (i.e. com.widgets.products2001.* and com.widgets.products2002.*). Starting
with Java 2, the classes pertaining to a package are stored in a particular directory
depending on the name of the package. This directory is always relative to the classes
directory. In a Windows system, this directory might be c:\jdk1.2.1\jre\classes while on a
UNIX machine it might be /usr/local/jdk1.2.1/jre/classes where /usr/local is the directory
where the JDK (Java Developer’s Kit) has been installed.
After the classes contained in a package are compiled they are installed in the directory
implied by the package name. In our case (assuming a standard Windows installation) the
directory is c:\jdk1.2.1\jre\classes\com\widgets. Note that com is a directory as well.
After compilation of the class which is part of the package, then name of the package
becomes part of the name of the class. In our case com.widgets.smallwidgets. In order to
use this class, we can use this complete name, or more easily, we can use the import
command to avoid using the complete name as shown below.
import com.widgets.smallwidgets;
public class Example {
. . .
Firstsmallwidget f1;
f1 = new Firstsmallwidget();
. . .
Java also provides a way to allow access to the methods and data members of one class to
be given to other classes which are part of the same package while not allowing access to
other classes. For example, we typically restrict access to the data members of classes,
allowing them only to be accessed using public methods – this is the basic philosophy of
ADTs.
package com.widgets.smallwidgets;
public class Firstsmallwidget extends Object {
private double widgetweight;
. . .
public double getWeight() { return widgetweight; }
. . .
The private keyword prevents other classes from directly accessing the widgetweight.
Instead they must use the getWeight method, which is declared public. On the other hand,
we may have auxiliary classes as part of the package which should be able to access the
widgetweight directly. We can have that result by declaring widgetweight to be
protected.
package com.widgets.smallwidgets;
public class Firstsmallwidget extends Object {
protected double widgetweight;
. . .
In order to have the same type of access in C++, it is necessary to explicitly list all of the
classes which are to have access to a private member as friend classes of the class in
question.
4.4 Generic Abstract Data Types
When we are working with ADTs like sets, queues and stacks, two distinct ADTs may
vary only in the type of element that is to be stored in the data structure. We may have
sets of integers, characters or strings, for example. Using the language constructs we have
seen so far, we would need to specify separate interfaces and have separate
implementations (i.e. a completely separate ADT) for each type of element we want to be
able to store in a structure. A little bit of thought will surely show that these separate
ADTs are in fact very much alike. Following this reasoning a little further, it would be
nice for the programming language we are using to allow us to give this common
structure once, rather than repeatedly, and have the parts specific for a particular element
type filled in when needed. This idea of giving the common part of an ADT and
instantiating it (specializing it) for a particular data type is the idea behind generic
abstract data types.
Generic abstract data types are supported in some, but not all, modern programming
languages. Ada supports generic ADTs through the generic package construct while C++
provides templates for the same purpose. We will focus on Ada generic packages in this
section.
In order to allow ADTs which work on various data types, Ada supports the generic
package construct. These packages are instantiated by users of the package. The
instantiation specializes the package, specifying the data type of the elements and also,
perhaps, some other parameters. In order to make a package generic, it is necessary to
make sure that there are no operations that are specific for one particular data type in the
procedures and functions in the package. This is usually not a problem since the types of
operations we are interested in are things like assignment and comparison that are valid
for most data types. The instantiation is accomplished using the new package operator.
The Ada package specification for a generic set ADT is given below.
-- Generic set package specification
-- Constraints: 0 <= get_set_size <= max_set_size
generic
type element_type is private;
package set_package is
type set(max_set_size
: positive) is limited private;
set_full
:exception;
set_empty
:exception;
function is_full (the_set : stack) return boolean;
-- Return value is true if list is full, false otherwise
function is_empty (the_set : stack) return boolean;
-- Return value is true if list is empty, false otherwise
procedure set_add (the_set : in out stack; element :
element_type);
-- element is added to the set
-- exceptions: set_full is raised if number of elements in the
-- set = max_set_size.
procedure set_remove (the_set : in out stack; element :
element_type);
-- If element is a member of the set, it is removed.
-- exceptions: set_empty is raised if number of elements in the
-- set = 0.
function get_set_size (the_set : set) return natural;
-- The size of the set is returned.
function set_union (first, second : set) return set;
-- Returns the union of the first and second sets.
function set_intersect (first, second : set) return set;
-- Returns the intersection of the first and second sets.
function set_difference (first, second : set) return set;
-- Returns the difference of the first and second sets.
function set_get_next_element (the_set : set) returns
element_type;
-- Returns the next set element.
private
type array_of_elements is array(positive range <>) of
element_type;
type set(max_set_size : positive) is record
current_elements
:natural := 0;
current_position
:natural := 0;
elements
:array_of_elements(1..max_set_size);
end record;
end natural_set_package;
The set type has been defined to be of type limited private. This is the more restrictive
alternative that Ada provides. If the set type had been declared private we would not be
able to manipulate its internal representation except through the given functions and
procedures of the type, but we would be able to assign it (using the assignment operator)
and to compare it to other sets using the equality operator. By declaring the type to be
limited private, these possibilities are not allowed. If we want, we can provide our own
assignment and equality operators for the set functions. So we can see that Ada provides
a very powerful information hiding capability that is useful in the implementation of
ADTS.
By making the size of the set a parameter, we give the user the ability to define the
maximum size of the set when it is declared. In this way Ada provides flexibility for the
different needs of different users.
4.5 Software Design with Abstract Data Types
The design of a software system is traditionally divided into a number of successive
phases. The phases are non-overlapping and each phase results in the production of one
or more documents. Two of the earliest stages are the analysis phase and the design
phase. The analysis phase is a detailed study of the problem to be solved. This is a crucial
phase in the production of large-scale software systems since even if we correctly
implement a solution, if the problem we are solving is not the one that the users are
interested in, we have not correctly solved the problem. Correcting such mistakes, which
often show up only when testing with real users begins, is very expensive since the whole
system may need to be reprogrammed. The design phase begins with a precisely detailed
description of the problem to be solved (the document which is the output of the analysis
phase) and gives a (possibly programming language independent) solution to the
problem. Only when the document describing this solution is produced does actual
coding in a programming language begin. These two phases may consume a large part of
the resources expended in developing a software system. Experience certainly suggests
that they should.
Even when implementing a software system using a programming language like C that
does not provide much support for the implementation of ADTs the use of ADTs in the
analysis and design phases of software development can be quite useful since it provides
a principled approach to the software development process.
Software design with ADTs generally begins with the description of a real-world problem
that needs to be understood. In the case of problems that require large systems to solve,
the real-world situation is often full of complicating details that make understanding the
problem difficult at best. Abstraction is a key tool in overcoming this difficulty. The idea
is to separate the pertinent details from those which are superfluous, abstracting away the
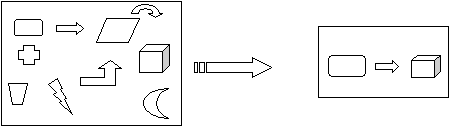
unnecessary details by creating a model of the problem as shown in figure 4.4.
Consider, for example, a simple system to keep track of grades for students on exams at a
university. We might start the design of a solution to this problem by identifying the
objects that are part of this problem – students, exams, instructors, etc. The next step in
the design might be to identify the attributes of these objects. For example, for student
ADTs we might have attributes such as:
• Name
• Age
• Address
• Identification number
• Major
• Eye color
• etc.
Clearly, some of these attributes (age, address, eye color) are not relevant to the problem
being solved and can be ignored in our model of the student ADT. In more realistic
problems, not just attributes of objects but entire objects may be safely ignored.
Figure 4.4 – Abstraction in System Design
The next step in the design process is to establish the operations that the various data
types should support. So, for example, the exam ADT will have operations such as
add_grade, change_grade, add_exam, etc. The interactions between the various ADTs
which comprise the system may also be established at this point as part of the
documentation of the system. All of the activities outlined until this point have been
independent of the language to be used in the implementation of the system. In the final
step, the ADTs will have to be implemented, and the ease with which this can be
accomplished will depend on the language to be used. If one has a library of previously
developed ADTs available and an object-oriented language is to be used for the
implementation, then part of the development process will likely include the
identification of a hierarchical organization of the ADTs (objects) in order to reuse as
much as possible of the programming work already done. The complete development
process outlined above is illustrated in figure 4.5.
Real World Problem
Simplified Model
Abstraction
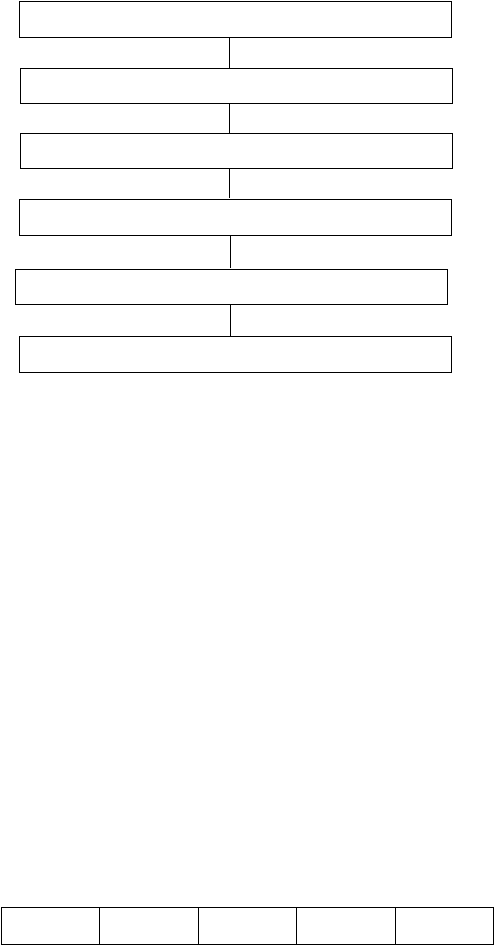
Figure 4.5 – System Design with ADTs
4.6 Conclusions
Data abstraction is one of the most important ideas to emerge the area of software
development in the last 30 years. Data abstraction was conceived as an idea to control the
explosion in program complexity that led many software projects to be completed late
and to contain many errors, and other projects to fail completely. Abstraction is an
effective tool to control complexity since it allows software designers to concentrate on
pertinent portions of a software project while ignoring irrelevant details. Data abstraction
is one of the two fundamental types of abstraction widely used in software design, along
with the older process abstraction, represented by the use of subprograms. Data
abstraction and the associated concept of ADTs did not become widely used, however,
until programming languages that support ADTs became widely available. Among these
languages, SIMULA 67 was a very early example (as was Smalltalk), but it was not
widely used in many application areas. Ada and Modula-2 were among the first widely
used languages that could easily support ADTs. They appeared in the early 1980s and
were followed by such important and popular object-oriented languages as C++ and Java.
The primary characteristics of ADTs are the collocation of a data structure and the
operations that manipulate that data structure and information hiding by allowing access
to the ADT only through the operations provided. SIMULA 67, Smalltalk, C++, Java and
other object-oriented languages support ADTs directly through their class structure.
Other languages, like Ada and Modula-2 provide a general encapsulation feature
(packages or modules) that can be used to indirectly simulate ADTs. Language structures
supporting ADTs for some of the languages we have examined in this chapter are
summarized below in Table4.1.
Separate
Compilation
Classes
Packages
Generics
Problem Definition
Identification of ADTs
Specify ADT operations
Specify ADT interactions
Identify object hierarchy (if using OO language)
Implement ADTs

C
Yes
No
No
No
C++
Yes
Yes
No
Yes
Java
Yes
Yes
Yes
No
Ada
Yes
No
Yes
Yes
Table 4.1 – ADT supporting Features of Some Popular Languages
The use of ADTs for software design was popularized by authors such as Grady Booch,
who developed the Booch methodology primarily for systems to be implemented in Ada.
The Booch methodology was later incorporated in the Uniform Modeling Language
which has been standardized by the Object Management Group and forms the basis for
many popular Computer-Aided Software Engineering (CASE) tools for the production of
large-scale software systems.
Exercises:
Beginner’s Exercises:
1. Consider a telephone as an Abstract Data Type. List the operations for the telephone
ADT.
2. Consider an automobile as an Abstract Data Type. List the operations for the telephone
ADT.
Intermediate Exercises:
3. Research a particular programming language and discuss its strengths and weaknesses
as a language for constructing ADTs.
4. Use ADTs to design a climate control system for a university campus. Give the ADTs
and their operations and show their interactions.
Advanced Exercises:
5. Use ADTs to design a system for automatic payment at toll road booths. Give the
ADTs and their operations and show their interactions.
6. Give the header file describing the ADTs, written in C, for either problem 4 or problem
5.