|
1
|
- Milos Hauskrecht
- milos@cs.pitt.edu
- 5329 Sennott Square
|
|
2
|
- Exam:
- April 18, 2007
- Term projects & project presentations:
- April 25, 2007
- At 1:00-4:00pm in SNSQ 5313
- No class:
- on April 23, 2007
|
|
3
|
- Mixture of experts
- Multiple ‘base’ models (classifiers, regressors), each covers a
different part (region) of the input space
- Committee machines:
- Multiple ‘base’ models (classifiers, regressors), each covers the
complete input space
- Each base model is trained on a slightly different train set
- Combine predictions of all models to produce the output
- Goal: Improve the accuracy of the ‘base’ model
- Methods:
- Bagging
- Boosting
- Stacking (not covered)
|
|
4
|
- Given:
- Training set of N examples
- A class of learning models (e.g. decision trees, neural networks, …)
- Method:
- Train multiple (k) models on different samples (data splits) and
average their predictions
- Predict (test) by averaging the results of k models
- Goal:
- Improve the accuracy of one
model by using its multiple copies
- Average of misclassification errors on different data splits gives a
better estimate of the predictive ability of a learning method
|
|
5
|
- Training
- In each iteration t, t=1,…T
- Randomly sample with replacement N samples from the training set
- Train a chosen “base model” (e.g. neural network, decision tree) on
the samples
- Test
- For each test example
- Start all trained base models
- Predict by combining results of all T trained models:
- Regression: averaging
- Classification: a majority vote
|
|
6
|
|
|
7
|
- Expected error= Bias+Variance
- Expected error is the expected discrepancy between the estimated and
true function
- Bias is squared discrepancy between averaged estimated and true
function
- Variance is expected divergence of the estimated function vs. its
average value
|
|
8
|
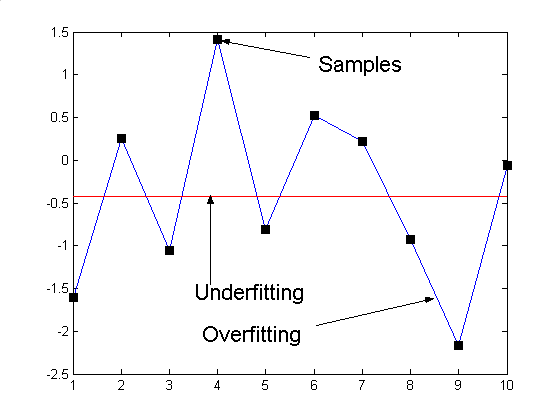
- Under-fitting:
- High bias (models are not accurate)
- Small variance (smaller
influence of examples in the training set)
- Over-fitting:
- Small bias (models flexible enough to fit well to training data)
- Large variance (models depend
very much on the training set)
|
|
9
|
- Example
- Assume we measure a random variable x with a N(m,s2) distribution
- If only one measurement x1 is done,
- The expected mean of the measurement is m
- Variance is Var(x1)=s2
- If random variable x is measured K times (x1,x2,…xk)
and the value is estimated as: (x1+x2+…+xk)/K,
- Mean of the estimate is still m
- But, variance is smaller:
- [Var(x1)+…Var(xk)]/K2=Ks2 / K2
= s2/K
- Observe: Bagging is a kind of averaging!
|
|
10
|
- Main property of Bagging (proof omitted)
- Bagging decreases variance of the base model without changing the
bias!!!
- Why? averaging!
- Bagging typically helps
- When applied with an over-fitted base model
- High dependency on actual training data
- It does not help much
- High bias. When the base model is robust to the changes in the training
data (due to sampling)
|
|
11
|
- Mixture of experts
- One expert per region
- Expert switching
- Bagging
- Multiple models on the complete space, a learner is not biased to any
region
- Learners are learned independently
- Boosting
- Every learner covers the complete space
- Learners are biased to regions not predicted well by other learners
- Learners are dependent
|
|
12
|
- PAC: Probably Approximately Correct
framework
- PAC learning:
- Learning with the pre-specified accuracy e and
confidence d
- the probability that the misclassification
error is larger than e is smaller than d
- Accuracy (e ): Percent of correctly classified samples in
test
- Confidence (d ):
The probability that in one experiment some accuracy will be achieved
|
|
13
|
- Strong (PAC) learnability:
- There exists a learning algorithm that efficiently learns the
classification with a pre-specified accuracy and confidence
- Strong (PAC) learner:
- A learning algorithm P that given an arbitrary
- classification error e (<1/2), and
- confidence d (<1/2)
- Outputs a classifier
- With a classification accuracy
> (1-e)
- A confidence probability >
(1- d)
- And runs in time polynomial in 1/ d, 1/e
- Implies: number of samples N is
polynomial in 1/ d, 1/e
|
|
14
|
- Weak learner:
- A learning algorithm (learner) W
- Providing classification accuracy
>1-eo
- With probability >1- do
- For some fixed and uncontrollable
- classification error eo (<1/2)
- confidence do
(<1/2)
- And this on an arbitrary distribution of data entries
|
|
15
|
- Assume there exists a weak learner
- it is better that a random guess (50 %) with confidence higher than 50
% on any data distribution
- Question:
- Is problem also PAC-learnable?
- Can we generate an algorithm P that achieves an arbitrary (e-d) accuracy?
- Why is important?
- Usual classification methods (decision trees, neural nets), have
specified, but uncontrollable performances.
- Can we improve performance to achieve pre-specified accuracy
(confidence)?
|
|
16
|
- Proof due to R. Schapire
- An arbitrary (e-d) improvement is
possible
- Idea: combine multiple weak learners together
- Weak learner W with confidence do and maximal error eo
- It is possible:
- To improve (boost) the confidence
- To improve (boost) the accuracy
- by training different weak
learners on slightly different datasets
|
|
17
|
|
|
18
|
- Training
- Sample randomly from the distribution of examples
- Train hypothesis H1.on the sample
- Evaluate accuracy of H1 on the distribution
- Sample randomly such that for the half of samples H1. provides
correct, and for another half, incorrect results; Train hypothesis H2.
- Train H3 on samples from the distribution where H1
and H2 classify differently
- Test
- For each example, decide according to the majority vote of H1,
H2 and H3
|
|
19
|
- If each hypothesis has an error eo, the final classifier has error <
g(eo)
=3 eo2-
2eo3
- Accuracy improved !!!!
- Apply recursively to get to the target accuracy !!!
|
|
20
|
- Similarly to boosting the accuracy we can boost the confidence at some restricted accuracy cost
- The key result: we can improve both the accuracy and confidence
- Problems with the theoretical algorithm
- A good (better than 50 %) classifier on all data problems
- We cannot properly sample from data-distribution
- Method requires large training set
- Solution to the sampling problem:
- Boosting by sampling
- AdaBoost algorithm and variants
|
|
21
|
- AdaBoost: boosting by sampling
- Classification (Freund, Schapire; 1996)
- AdaBoost.M1 (two-class problem)
- AdaBoost.M2 (multiple-class
problem)
- Regression (Drucker; 1997)
|
|
22
|
- Given:
- A training set of N examples (attributes + class label pairs)
- A “base” learning model
(e.g. a decision tree, a
neural network)
- Training stage:
- Train a sequence of T “base” models
on T different sampling distributions defined upon the training set (D)
- A sample distribution Dt for building the model t is
constructed by modifying the
sampling distribution Dt-1 from the (t-1)th step.
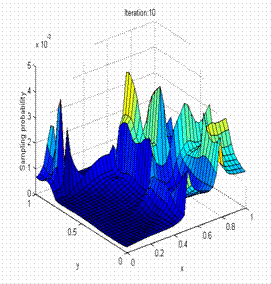
- Examples classified incorrectly in the previous step receive higher
weights in the new data (attempts to cover misclassified samples)
- Application (classification) stage:
- Classify according to the weighted majority of classifiers
|
|
23
|
|
|
24
|
- Training (step t)
- Sampling Distribution
- - a probability that
example i from the original training dataset is selected
- Take K samples from the training set according to
- Train a classifier ht on the samples
- Calculate the error of ht :
- Classifier weight:
- New sampling distribution
|
|
25
|
|
|
26
|
|
|
27
|
- We have T different classifiers h
t
- weight wt of the classifier is proportional to its accuracy
on the training set
- Classification:
- For every class j=0,1
- Compute the sum of weights w corresponding to ALL classifiers that
predict class j;
- Output class that correspond to the maximal sum of weights (weighted
majority)
|
|
28
|
- Classifier 1 “yes” 0.7
- Classifier 2 “no” 0.3
- Classifier 3 “no” 0.2
- Weighted majority “yes”
- The final choose is “yes”
+ 1
|
|
29
|
- Each classifier specializes on a particular subset of examples
- Algorithm is concentrating on “more and more difficult” examples
- Boosting can:
- Reduce variance (the same as Bagging)
- But also to eliminate the effect of high bias of the weak learner
(unlike Bagging)
- Train versus test errors performance:
- Train errors can be driven close to 0
- But test errors do not show overfitting
- Proofs and theoretical explanations in a number of papers
|
|
30
|
|
|
31
|
- An alternative to combine multiple models: can be used for supervised
and unsupervised frameworks
- For example:
- Likelihood of the data can be expressed by averaging over the multiple
models
- Prediction:
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
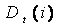{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
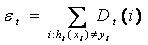{kind=link}
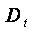{kind=link}
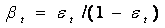{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
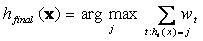{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}